


NVIDIA在GTC 2022技术大会中正式发布次世代GPU架构Hopper,并提出多种不同组合产品,大幅提高加速运算的应用弹性。
Hopper架构正式登场
在去年GTC 2021春季场中,NVIDIA发布了专为AI超级运算设计的Grace处理器,它采用Arm处理器架构,支持LPDDR5x内存子系统,并透过第4代NVLink汇流排技术,提供处理器与GPU(绘图处理器)之间高达900 GB/s的数据传输速度,与当今技术领先的服务器相比,聚集带宽增益达30倍。 Grace也将采用LPDDR5x内存子系统,与目前的DDR4内存相比,能够提供2倍的带宽以及10倍的能源效率。
Grace的名称来自美国编程先驱葛丽丝‧穆雷‧霍普(Grace Murray Hopper),而这次发表的GPU架构Hopper,也是以她为名。
H100为首款采用Hopper架构的GPU,它采用台积电4N节点制程,具有800亿个晶体管搭载HBM3高带宽内存并支持PCIe Gen5总线与高度可扩展的NVIDIA NVLink互连技术,是世界上最先进且最强大的加速运算单元。
全新的Transformer Engine自然语言处理模型是有史以来最重要深度学习模型发明之一,它能够在不牺牲准确性的前提下提高6倍运算速度,而全新的DPX指令加速动态规划(Dynamic Programming)可以在路线规划、基因组学 等领域带来40倍于处理器或7倍于前代GPU的效能,为人工智能应用注入强大动能。
此外H100也支持机密运算(Confidential Computing),以及NVIDIA第二代多执行个体GPU(Multi-Instance GPU,MIG), 支持完整的每执行个体隔离和每执行个体 IO 虚拟化功能,并可支持托管7个云端租用户, 能提高整体资安可靠度,更加适合医疗保健和金融服务、公有云、 联邦学习(Federated Learning)等需要高安全性的应用。
 ▲ H100为首款采用Hopper架构的GPU,能在不牺牲准确性的前提下提高6倍运算速度。
▲ H100为首款采用Hopper架构的GPU,能在不牺牲准确性的前提下提高6倍运算速度。
 ▲ H100将成为世界上最先进的芯片,并支持Transformer Engine、DPX指令加速动态规划等重要功能。
▲ H100将成为世界上最先进的芯片,并支持Transformer Engine、DPX指令加速动态规划等重要功能。
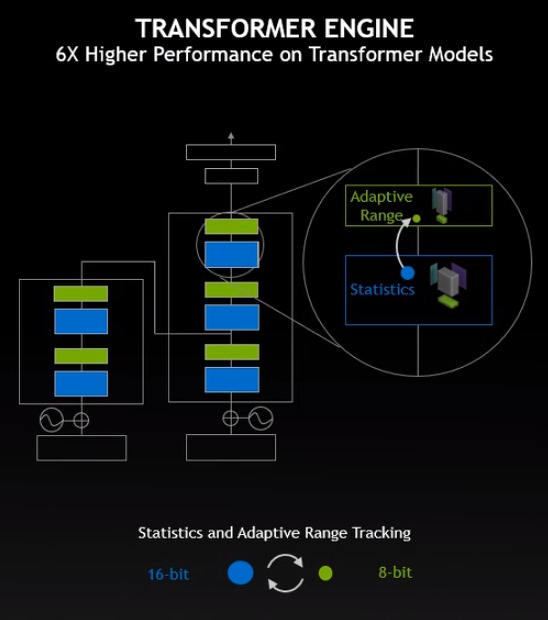 ▲ Transformer Engine能够自动按数据类型进行优化, 在不牺牲准确性的前提下提高6倍运算速度 。
▲ Transformer Engine能够自动按数据类型进行优化, 在不牺牲准确性的前提下提高6倍运算速度 。
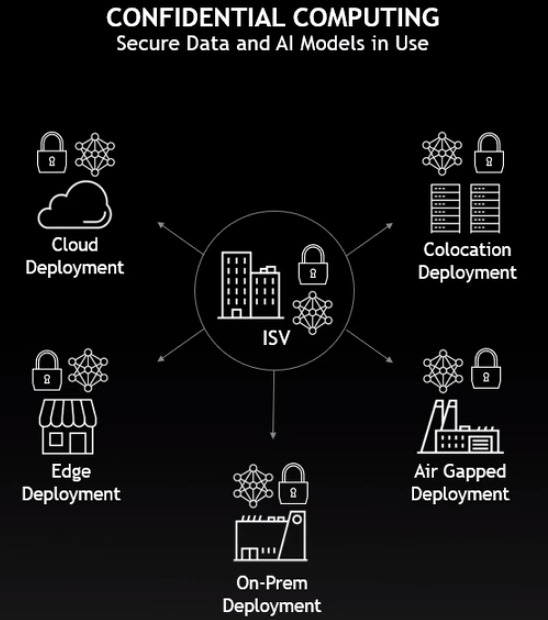 ▲ 机密运算适合医疗保健和金融服务、公有云、联邦学习等需要高安全性的应用。
▲ 机密运算适合医疗保健和金融服务、公有云、联邦学习等需要高安全性的应用。
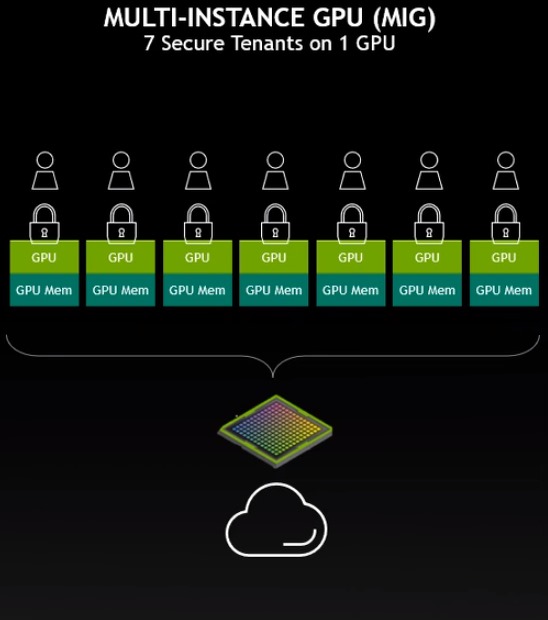 ▲ NVIDIA第二代多执行个体GPU能将1个实体GPU切割成7个执行个体,兼顾安全性与资源分配弹性。
▲ NVIDIA第二代多执行个体GPU能将1个实体GPU切割成7个执行个体,兼顾安全性与资源分配弹性。
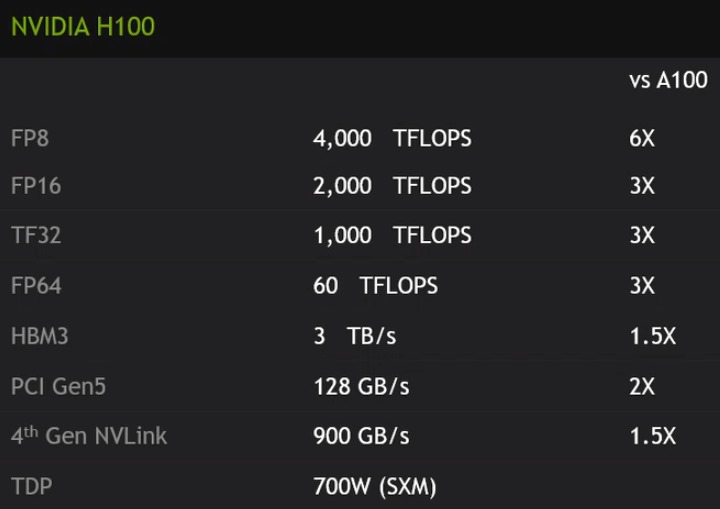 ▲ 与前代A100相比,H100在FP8数据类型运算中有6备效能表现。
▲ 与前代A100相比,H100在FP8数据类型运算中有6备效能表现。
 ▲ H100在多种应用情境的效能表现也大幅领先A100。
▲ H100在多种应用情境的效能表现也大幅领先A100。
推出多种组合产品
Hopper架构的H100 GPU将可与Grace处理器共同组成Grace Hopper超级芯片,NVIDIA也将推出整合2颗Grace处理器的Grace CPU超级芯片,裸晶(Die)之间采用NVLink-C2C互连技术,以满足高速、低延迟、芯片间数据传输的需求,并将推出多种不同的配置选项,为次世代服务器带来更有弹性的建构选择。
根据NVIDIA提供的资料,Grace CPU超级芯片具有144个Arm架构处理器核心,SPECrate 2017_int_base性能测试成绩推测将高达740分,是DGX A100电脑中双处理器效能的1.5倍以上。
焦点回到H100 GPU,它采用台积电CoWoS 2.5D封装技术,将GPU与HBM3内存等组件封装在一起,并将推出SXM模块版本。 以DGX H100电脑为例,它将8个H100 SXM模组安装至HGX主板,并透过4个NVLink交换器芯片连线,将8个H100变成一个巨型GPU,提供32 petaFLOP人工智能效能,将成为人工智能工厂的最小的组成单位。
需要更大量运算效能的用户,可以通过这次推出的NVIDIA NVLink交换器系统,使用NVLink连接32台DGX H100,将其扩展为单一的大型32节点256 GPU的DGX SuperPOD。
此外NVIDIA宣布正在打造由18台DGX SuperPOD(576台DGX H100、4608组H100 GPU)组成的Eos超级计算机其传统的科学运算(FP64数据类型)的效能为275 petaFLOPS,比搭载A100 GPU、目前美国最快的科学计算机Summit快了1.4 倍。 而在在人工智能方面(FP8数据类型),Eos的运算效能为18.4 Exaflops,比目前全世界最快的超级计算机Fugaku(富岳)高出4倍。 待它完成部署后,有望成为世界上最快的人工智能电脑,NVIDIA创办人兼执行长黄仁勋在GTC 22春季展开幕演说中表示,对Eos充满信心,而Eos将在数个月内上线。
此外NVIDIA也会推出PCIe适配卡型式的H100运算卡,而这次还发表了具有独立网络介面的H100 CNX运算卡。 它最大的特色就是整合Connectx-7网络芯片,可以略过节点上的处理器,直接访问外部节点的数据,不但有助于提升数据吞吐量,也能降低处理器使用率,对现有服务器的升级很有吸引力。
 ▲ Grace Hopper超级芯片将整合Grace处理器与Hopper GPU,裸晶之间透过NVLink-C2C互相连接。
▲ Grace Hopper超级芯片将整合Grace处理器与Hopper GPU,裸晶之间透过NVLink-C2C互相连接。
 ▲ Grace CPU超级芯片则是整合2颗Grace处理器,总共具有144个Arm架构处理器核心。
▲ Grace CPU超级芯片则是整合2颗Grace处理器,总共具有144个Arm架构处理器核心。
 ▲ Grace超级芯片的高画质渲染图。
▲ Grace超级芯片的高画质渲染图。
 ▲ Grace Hopper超级芯片具有高度配置弹性,用户可以选择「双Grace CPU超级芯片」、「单一 Grace + 单一Hopper超级芯片」、「单一 Grace + 双 Hopper 超级芯片」、「双Grace + 双Hopper系统」、「双 Grace + 4 Hopper系统」、「双Grace + 8 Hopper系统」。
▲ Grace Hopper超级芯片具有高度配置弹性,用户可以选择「双Grace CPU超级芯片」、「单一 Grace + 单一Hopper超级芯片」、「单一 Grace + 双 Hopper 超级芯片」、「双Grace + 双Hopper系统」、「双 Grace + 4 Hopper系统」、「双Grace + 8 Hopper系统」。
 ▲ H100 GPU将推出SXM模块版本,DGX H100电脑则由8个H100 SXM模组构成。
▲ H100 GPU将推出SXM模块版本,DGX H100电脑则由8个H100 SXM模组构成。
 ▲ NVIDIA也将推出搭载H100的DGX电脑与SuperPOD超级计算机。
▲ NVIDIA也将推出搭载H100的DGX电脑与SuperPOD超级计算机。
 ▲ H100将会有多种不同尺度的对应产品,以满足各种应用情境不同的需求。
▲ H100将会有多种不同尺度的对应产品,以满足各种应用情境不同的需求。
 ▲ NVIDIA正在打造由576台DGX H100组成的EOS超级计算机,待它完成部署后将成为世界上最先进的计算机。
▲ NVIDIA正在打造由576台DGX H100组成的EOS超级计算机,待它完成部署后将成为世界上最先进的计算机。
 ▲ 各节点将由新推出的NVLink交换器传输数据,大幅提升存取效能。
▲ 各节点将由新推出的NVLink交换器传输数据,大幅提升存取效能。
 ▲ H100 CNX可以视为具有独立网络接口的H100加速运算单元。
▲ H100 CNX可以视为具有独立网络接口的H100加速运算单元。
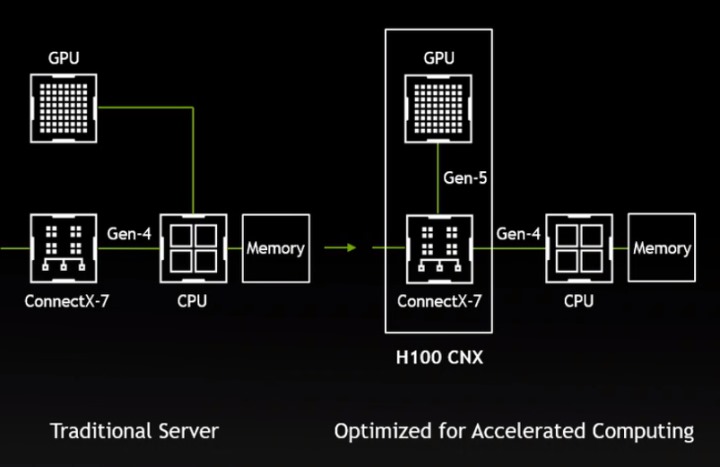 ▲ H100 CNX能够略过中央处理器,直接透过,并由卡上的网络介面与PCIe Gen 5总线存取数据。
▲ H100 CNX能够略过中央处理器,直接透过,并由卡上的网络介面与PCIe Gen 5总线存取数据。
目前GTC22正在进行中,有兴趣参与的读者可以参考《NVIDIA将于3月21日至24日举办GTC 2022技术大会,即日起免费报名》一文,免费注册并参加线上会议以及超过900场主题演说。
 微信扫一扫
微信扫一扫
相关推荐
-
有爱再来! 粉丝向手游《炎炎消防队 炎舞之章》试玩心得
《炎炎消防队 炎舞之章(炎炎ノ消防队 炎舞ノ章)》为原作 大久保笃 绘制《炎炎消防队》漫画所改编的回合制角色扮演游戏,由日本Mobcast Games和extra mile共同负责…
-
微软宣布 2017 年推出的 Windows Mixed Reality 已终结
早在今年年初,微软解散了 Windows Mixed Reality、AltspaceVR 和 MRTK 的整个团队。 当时,微软宣布将停止 AltspaceVR 和 MRTK 的…
-
M3 MacBook Air SSD 升级 256GB 告别读写缓慢问题
M3 MacBook Air发布后,不少人也在选择 256GB 或 512GB 之间有疑问,原因不于容量,而是 M2 MacBook Air 的 256GB 版比 512GB 版慢…
-
NFT 被盗又一起!OpenSea 遭黑客攻击,32 用户价值 170 万美元的 NFT 被盗
NFT(Non-Fungible Token,非同质化代币)在全球日渐升温,也接连传出不少犯罪事件。据美国消费者新闻与商业频道 CNBC 报道,NFT 市场 O…
-
动物餐厅最新兑换码总整理! 序号的使用期限、条件一览!
手游《Animal Restaurant 动物餐厅》可以说是一个老少咸宜、可爱又放置的手游,小编这里帮大家统整了动物餐厅的兑换码,以及兑换的方式,通通都在这啰! 动物餐厅兑换码这边…
-
升级iOS 17.1.1要三思! 实测:iPhone电力最高衰退50分钟
苹果在本周释出iOS 17.1.1更新,主要修复两大Bug,包括iPhone的「天气」锁定画面小工具无法正常显示降雪,以及iPhone 15在特定汽车内无线充电后,使得Apple …