
AMD回应NVIDIA的H100 TensorRT-LLM结果,再次显示MI300X GPU使用优化的AI软件堆叠效能提升30%
AMD对NVIDIA的H100 TensorRT-LLM数据做出回应,MI300X在运行优化时再次在AI测试中处于领先地位软件。
两天前NVIDIA发布了其Hopper H100 GPU的新测试以展示他们的芯片性能比AMD展示的要好得多,在推进人工智能期间AMD将其全新的Instinct MI300X GPU 与Hopper H100芯片进行了比较,后者已经推出一年多了,但仍然是人工智能行业最受欢迎的选择。 AMD使用的测试并未使用TensorRT-LLM等优化库,而TensorRT-LLM为NVIDIA的AI芯片提供了巨大的提升。

使用TensorRT-LLM使Hopper H100 GPU的性能比AMD的Instinct MI300X GPU提高了近50%。 现在AMD正全力反击NVIDIA,展示MI300X如何在Hopper H100 运行其优化的软件堆叠时仍然保持比H100更快的效能。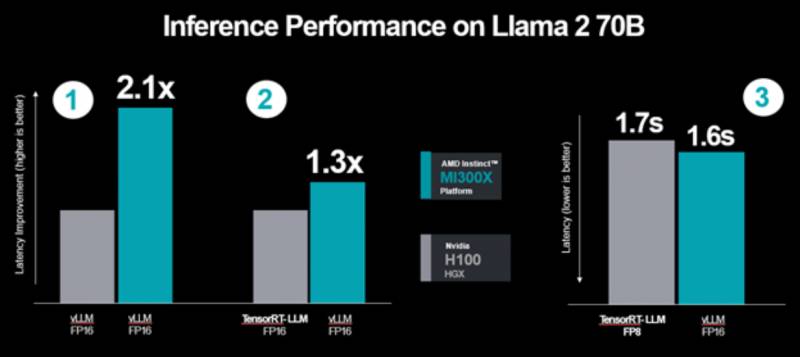
- 在H100上使用TensorRT-LLM,而不是AMD测试中使用的vLLM
- AMD Instinct MI300X GPU上的FP16数据型别与H100上的FP8数据类型的性能比较
- 将AMD发布的性能数据从相对延迟数转换为绝对吞吐量
因此AMD决定进行更公平的比较,根据最新数据我们发现在vLLM上运行的Instinct MI300X比在TensorRT-LLM上运行的Hopper H100性能提高了30%。
当然这些来回的数字有些出乎意料,但考虑到人工智能对于AMD、NVIDIA和Intel等公司的重要性,我们可以期待看到更多这样的例子被分享未来。 就连Intel最近也表示整个产业都在积极推动终结NVIDIA CUDA在产业中的主导地位。 目前的事实是英伟达在人工智能领域拥有多年的软件专业知识,虽然Instinct MI300X提供了一些可怕的规格,但它很快就会与更快的Hopper解决方案展开竞争。
 微信扫一扫
微信扫一扫
相关推荐
-
《剑侠世界3》天忍门派入门
门派定位 天忍作为近战输出门派,目前是所有门派中输出最高的角色之一,她的技能组在造成大量伤害的同时,拥有丰富的的位移,灵活就是天忍的代名词。 她也正因如此,通过瞬间进场造成击杀,拥…
-
最后信息iPhone 15及15 Plus新改进率先看
Apple于9月13日凌晨1时发布会将会有4款新iPhone登场,分别为iPhone 15、15 Plus、15 Pro及15 Pro Max。 今年的基础版iPhone 15和1…
-
晴空物语 | 每日游玩信息解说
晴空物语手游版,每日限时活动的内容有点凌乱,这篇信息我来做一个每日游玩的小整理,还有每天需要游玩的部分,让你天天不漏接资源 点开游戏桌 > 时程查询 这边有对应每日的活动,因…
-
甘道夫醒醒啦|零氪与微氪,火球流冰锥流雷击流攻略
许多玩家在游戏中经常感到困惑,不知道如何以最具性价比的方式进行付费,因此今天我们将与大家分享零花费的资源获取方式以及微氪应该如何进行。 零氪玩家 对于零花费玩家来说,唯一的资源来源…
-
卡巴斯基:iOS「官方后门」或长期被黑客利用 「三角测量行动」漏洞轻易窃取用户私隐
Kaspersky(卡巴斯基)日前在第 37 届 Chas Communication Congress (CCC)大会上揭露了 iOS 的「三角测量行动」(Operation T…