


生成式 AI 模型正在迅速进化,并提供精密性与功能。 这项技术进展得以让各产业的企业与开发人员解决复杂的问题,并发掘新商机。 不过生成式 AI 模型的成长,也导致训练、调整与推论方面的要求变得更加严苛。
过去五年来,生成式 AI 模型的参数每年增加十倍,现今的大型模型具有数千亿、甚至数兆项参数,即便使用最专门的系统,仍需要相当长的训练时间,有时需持续数月才能完成。 此外,高效率的 AI 工作负载管理需要一个具备一致性、且由优化的运算、存储、网络、软件和开发框架所组成的集成AI 堆栈。
为解决这些难题,谷歌 推出 Cloud TPU v5p,这是功能最强大、扩展能力最佳,且最具有弹性的 AI 加速器。 长久以来,TPU 一直是用来训练、服务 AI 支持的产品之基础,这类产品包含 YouTube、Gmail、谷歌 地图、谷歌 Play 及 Android。 事实上,谷歌 日前宣布推出的 AI 模型 Gemini 便是使用 TPU 进行训练与服务。
此外,这次还推出 谷歌 Cloud AI Hypercomputer。 AI Hypercomputer 是 谷歌 Cloud 的超级计算机架构,采用一体化系统,并结合了性能优化硬件、开放式软件、领先机器学习架构及灵活弹性的消费模式。 传统上通常是以零碎的方式,在元件层级进行增强以处理要求严苛的 AI 工作负载需求,而这可能导致效率不佳,或出现瓶颈。 相较之下,AI Hypercomputer 采用系统层级的协同设计来提升 AI 训练、调整与服务的效率与生产力。
探索 Cloud TPU v5p:谷歌 Cloud 目前功能最强大、扩充能力最佳的 TPU 加速器
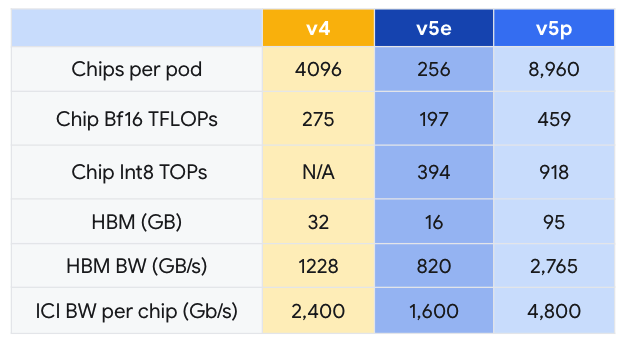
谷歌 在 2023 年 11 月宣布全面推出 Cloud TPU v5e。 相较于上一代的TPU v4,Cloud TPU v5e的性价比提高了2.3倍,是目前最具成本效益的TPU。 而Cloud TPU v5p则是目前功能最强大的TPU。 每个TPU v5p Pod均由8,960个芯片组成,透过带宽最高的芯片间互连网络(Inter-chip Interconnect,ICI)相连,采用3D环面拓扑,提供每芯片4,800 Gbps的速度。 相较于TPU v4,TPU v5p每秒的浮点运算次数(FLOPS)提高2倍以上,高带宽记忆体(High-bandwidth Memory,HBM)则增加3倍。
TPU v5p 专为效能、弹性与大规模作业而设计,相较于前一代的TPU v4,TPU v5p训练大型LLM模型的速度提升2.8倍。 不仅如此,若搭配第二代 SparseCores,TPU v5p 训练嵌入密集模型的速度较 TPU v4 快 1.9 倍。
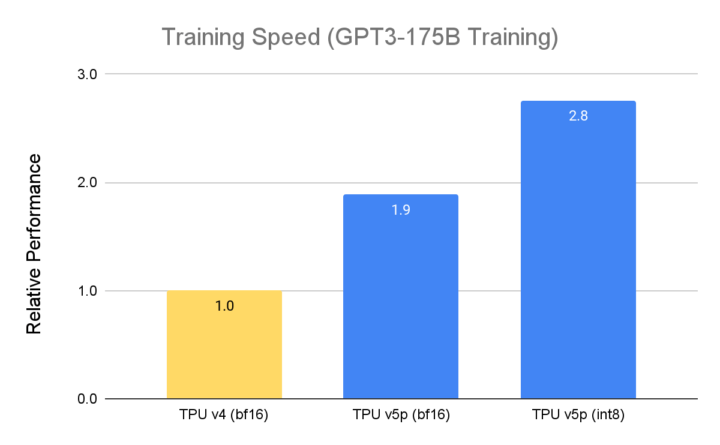
资料来源:谷歌 内部资料,截至 2023 年 11 月, GPT3-175B 的所有数据均以芯片为单位完成标准化作业
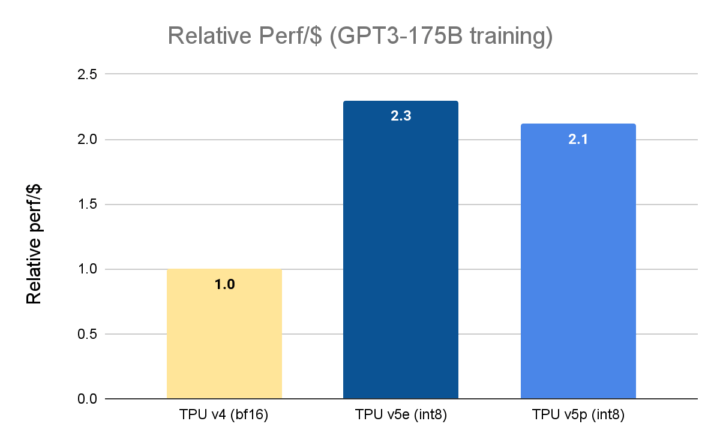
数据来源:TPU v5e 数据来自MLPerf™ 3.1 Training Closed 的 v5e 结果; TPU v5p 及 v4 数据来自 谷歌 内部执行的训练作业。 截至2023年11月,GPT-3 1750亿参数模型的所有数据均以每芯片seq-len=2048为单位完成标准化,并以TPU v4:$3.22美元/芯片/小时、TPU v5e: $1.2美元/芯片/小时、以及TPU v5p:$4.2美元/芯片/小时的公开定价显示每美元相对的效能
TPU v5p 不仅性能更优异,就每 Pod 的总可用 FLOPS 而言,TPU v5p 的扩充能力较 TPU v4 高 4 倍,且 TPU v5p 每秒的浮点运算次数(FLOPS)是 TPU v4 的两倍,并在单一 Pod 中提供两倍的芯片,可大幅提升训练速度的相对效能。
谷歌 AI Hypercomputer 大规模提供顶尖效能与效率
达到规模和速度是必要,但并不足以满足现代AI/ML应用程序与服务的需求。 软硬件元件必须相辅相成,组成一个易于使用、安全可靠的整合式运算系统。 谷歌 已针对此问题投入数十年的时间进行研发,而 AI Hypercomputer 正是我们的心血结晶。 此系统集结了多种能协调运作的技术,能以最佳方式来执行现代 AI 工作负载。

- 效能优化硬件:AI Hypercomputer 以超大规模数据中心基础架构为构建基础,采用高密度足迹、水冷技术以及我们Jupiter数据中心网络技术,在运算、储存与网络功能上皆能提供最佳性能。 上述一切均仰赖以效率为核心的技术,不仅采用洁净能源,并深耕水资源管理,协助我们朝无碳未来迈进。
- 开放式软件:透过AI Hypercomputer,开发人员即可使用开放式软件访问谷歌的性能优化硬件,利用这些硬件调整、管理及动态调度管理AI训练与推论的工作负载。
- 广泛支持多种热门机器学习架构(例如 JAX、TensorFlow 与 PyTorch),全可立即使用。 如要建立复杂的 LLM,JAX 与 PyTorch 均采用 OpenXLA 编译器。 XLA 作为基础骨干,提供建立复杂多层式模型的功能 (可参阅 在 Cloud TPU 上使用 PyTorch/XLA 进行 Llama 2 训练与推论的说明)。 XLA 会将广泛硬件平台的分布式架构调整至最佳状态,确保各种 AI 用途的模型开发作业既简单又有效率(可参阅 AssemblyAI 在大规模 AI 语音技术中运用 JAX/XLA 与 Cloud TPU 的说明)。
- 提供开放且独特的 Multislice Training及Multihost Inferencing 软件,分别使扩充、训练与提供模型的工作负载变得流畅又简单。 若要处理需求严苛的 AI 工作负载,开发人员可将芯片数量扩充至数万个。
- 深度整合 谷歌 Kubernetes Engine(GKE) 及 谷歌 Compute Engine,已提供有效率的管理资源、一致的作业环境、自动调度资源、自动布建节点集区、自动查核点、自动续传,并实时进行故障恢复等作业。
- 灵活弹性的消费模式:AI Hypercomputer提供广泛且弹性的动态消费选择。 除了承诺使用折扣(Committed Used Discunts, CUD)、以量计价与现货价格等传统选项,AI Hypercomputer 也透过Dynamic Workload Scheduler 提供专为 AI 工作负载量身打造的消费模式。 Dynamic Workload Scheduler 包含两种消费模式:Flex Start Mode 可取得更多资源,且价格实惠,Calendar Mode 则适用于工作开始时间较容易预测的工作负载。
 微信扫一扫
微信扫一扫
相关推荐
-
采用 Asetek 8th Gen 方案,ASUS 公布 Ryujin III 一体式水冷
新一代的 Ryujin III 一体式水冷要来了。 接续 RYUO III 之后,ASUS 终于公布了采用 Asetek 8th Gen 方案的 ROG Ryujin III 系列…
-
苹果释出iOS 17.1.2正式版 用户快更新! 修复两大安全漏洞
苹果在1日推出iOS 17.1.2正式版,提供iPhone用户们更新。 而此次更新主要是修复安全漏洞,并没有特别增加其他新功能,对此官方呼吁用户,此次更新提供重要的安全性修正,建议…
-
是天才还是暴君? 特斯拉前经理告诉你,他看到在工作中的马斯克的8个真相
埃隆·马斯克(Elon Musk)是一位备受争议的CEO。 科技圈里流传着许多马斯克的故事,说他睡在特斯拉工厂里,喜欢解雇员工。 实际情况真的是这样吗? 听听与马斯克一起共事过的前…
-
微信快速赚100块不收费用(这样的羊毛你薅不薅)
微信快速赚100块不收费用,这是一个很多人都想知道的答案。其实,只要会玩,100块是非常容易赚到的。 首先,你需要关注一些微信公众号,这些公众号会不定期发布一些任务,要求你去完成一…
-
《只狼:暗影双死》全球累积销量破1000万! 玩家敲碗想要续作
由 FromSoftware 在 2019 年推出的动作冒险游戏《只狼:暗影双死》(Sekiro: Shadows Die Twice),全新的高速战斗与体干值的设定,获得了玩家们…
-
开发商确认《PAYDAY 3》计划发行后升级到Unreal Engine 5引擎
关于游戏使用的引擎,FAQ中写道:「Unreal Engine 4。 我们开始在Unreal 4上开发游戏,所以这是我们发布的最合理选择。 我们计划在发行后升级到Unreal En…