


使用 Metal API 的应用程序和游戏以 Apple Silicon GPU 的特定功能为目标,M3 和 A17 Pro 的平行处理能力得到了显著提升,使其性能更上一层楼。 苹果公司发布了关于这些新的 Apple Silicon GPU 功能的开发者讲座,详细介绍了实现改进效果的具体过程。 介绍了大量技术细节,但也提供了足够的基本解释。
使用 Metal API 构建应用程序的开发者无需对其应用程序做任何修改,就能看到 M3 和 A17 Pro 的性能提升。 这些芯片组利用动态快存、硬件加速光线追踪和硬件加速网格对应技术,使GPU的性能空前提高。
动态着色器核心内存
目录

▲ 虚线表示浪费的寄存器内存
通常情况下,GPU 只能根据一个已执行动作中带宽最高的处理程序来分配暂存器内存,并持续该动作。 因此,如果一个动作的某个部分比其他部分需要更多的寄存器内存,那么该动作的某个处理程序就会占用更多的暂存器内存。
动态缓存允许 GPU 为其正在执行的每个操作精确分配适量的寄存器内存。 以前不可用的暂存器内存被释放出来,从而可以平行执行更多的着色器任务。
灵活的on-chip memory
以前,on-chip memory会为寄存器、线程组和带有缓冲快取的磁贴内存分配固定的内存。 这意味着,如果某项操作使用的内存类型多于另一种,就会有很大一部分内存被闲置。
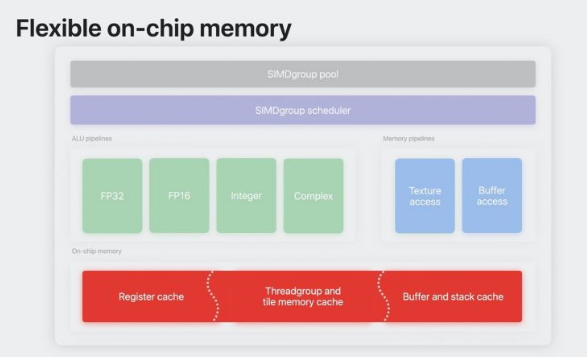
▲ 整个芯片内存都可用作快取内存
有了灵活的on-chip memory,所有内存都是快取,可用于任何内存类型。 因此,严重依赖执行绪组内存的操作可以利用整个片上内存,甚至溢出到主内存中。
着色器核心可动态调整内存占用率,以最大限度地提高性能。 这意味着开发人员可以花更少的时间来优化占用率。
着色器核心的高性能 ALU 管线
Apple 建议开发人员在程序中执行FP16数学运算,但高性能ALU可平行执行整数、FP32和FP16的不同组合。 指令在平行执行的不同操作中执行,这意味着 ALU 利用率会随着占用率的提高而提高。

▲ 利用高性能 ALU 流水线增加平行操作
基本上,如果不同的操作包含相同的FP32或FP16指令,而这些指令将在不同的时间点执行,则可以重叠执行以提高平行性。
硬件加速图形流水线
硬件加速的光线追踪可将重要的交点计算从 GPU 功能中移除,从而大大加快处理速度。 由于部分计算由硬件完成,因此可以平行进行更多操作,从而通过硬件元件加速光线追踪。
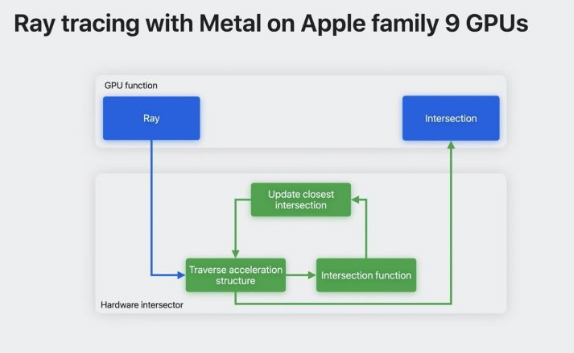
▲ 硬件加速取代片上处理程序
硬件加速网格着色采用了类似的方法。 它将几何计算流水线的中间部分交给一个专用单元,从而实现更多平行操作。
这些都是复杂的系统,不是几段文字就能说清楚的。 建议大家观看官方视频《Explore GPU advancements in M3 and A17 Pro》了解所有细节,并牢记一点–A17 Pro 和 M3 专注于计算平行性,以加快任务执行速度。
M3 可用于 MacBook Pro 和 24 英寸 iMac。 A17 Pro 可用于iPhone 15 Pro。
 微信扫一扫
微信扫一扫
相关推荐
-
Intel的下一代Battlemage Xe2和Celestial Xe3 dGPU和Panther Lake。 Nova Lake iGPU在HWiNFO中获得支持
Intel采用Battlemage和Celestial架构的下一代独立和整合GPU,适用于Panther Lake和Nova Lake等产品已获得HWiNFO支持。 即将推出的HW…
-
S.H.F 孙悟空-传说的超级撒亚人 可动性超高 + 造工好 + 配件多
提起拥有金色头发,战斗力惊人,你会想起什么动漫人物? 相信大家都会想到经典动漫作品龙珠的超级撒亚人孙悟空,Dragon Ball Z Legenary Super Saiyan S…
-
30% 商店上架费太贵了? Sony 因此面临集体诉讼
Sony在国外被告上了法院,面临一起价值超过79亿美元的集体诉讼,因为其PlayStation Store要求的30%交易税太高了。 而索尼的律师希望撤销诉讼的努力失败,因此双方现…
-
开放宇宙多元玩法建国游戏 《SpaceBourne 2》登陆Steam
由Burak Dabak开发发行的宇宙探索单人TPS游戏《SpaceBourne 2》于今日登陆Steam商店,并放出了该作首部预告,该作预计于今年11月2日发售,本作使用UNREAL 4引起擎开发,一起来看看吧!
-
日本角色扮演游戏《永恒光辉》将于1月13日在任天堂Switch和索尼Playstation上推出!
去年12月先于 Steam 上市,并获得极度好评的动作角色扮演游戏《永恒光辉》(Eternal Radiance)宣布,主机版将于 2022 年 1 月 13 日在任天堂 Swit…
-
入手大屏幕iPhone最佳时机? 等待iPhone 15 Plus会更值得
自从苹果推出iPhone 14系列后,直接将小尺寸mini机型改为大屏幕尺寸iPhone 14 Plus后,没想到iPhone 14 Plus需求与销量呈现非常低迷,直到最近有知名…