


在完成程序与模型的安装后,终于可以开始动手玩AI算图啦,不过还请大家克制一下歪楼的欲望,先让我们熟悉一下Stable Diffusion WebUI的操作界面。
SD启动!
在一切就绪后,可以参考先前2-1章节的方式启动Stable Diffusion WebUI,不过为了简化操作流程,我们可以先将Anaconda Prompt制作桌面捷径,然后在桌面建立1个纯文本文件将下列文字写入档案中,然后将重新命名为「SD Launch.bat」,方便快速将启动指令复制到剪贴簿。 (假设stable-diffusion-webui文件夹放置于F:\Stable Diffusion\路径下,读者可依自身情况调下列述参数)
@echo off
(
echo F:
echo cd F:\Stable Diffusion\stable-diffusion-webui
echo .\RunSD.bat
echo.
) | clip
如此一来,只需先双击「SD Launch.bat」档案,然后在Anaconda Prompt捷径点击鼠标右键并选择以系统管理员身份执行,并在跳出的窗口上点击鼠标右键,就会贴上指令并开启Stable Diffusion WebUI后台程式。 这时候只要在电脑上打开浏览器,并输入「127.0.0.1:7860」的IP位置,就能连接到Stable Diffusion WebUI网页界面。
如果读者在先前在「RunSD.bat」有加入–listen参数,即可在同一区域网络内透过「<该计算机IP位置>:7860」连入,包括透过智慧型手机操作也没问题。 若是有加入–share参数,则可藉由Anaconda窗口中提示的网址,由外部网络电脑连入操作。
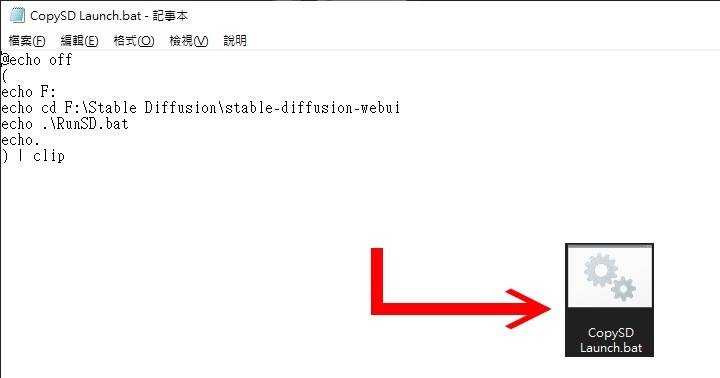 ▲ 将上述指令输入储存为 SD Launch.bat批次文件。
▲ 将上述指令输入储存为 SD Launch.bat批次文件。
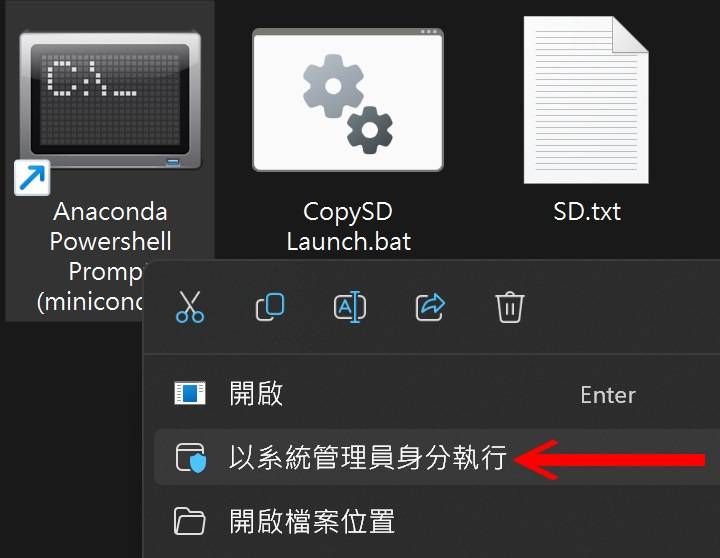 ▲ 要启动Stable Diffusion WebU时只需双击「SD Launch.bat」文件,并以系统管理员身份执行Anaconda Prompt。
▲ 要启动Stable Diffusion WebU时只需双击「SD Launch.bat」文件,并以系统管理员身份执行Anaconda Prompt。
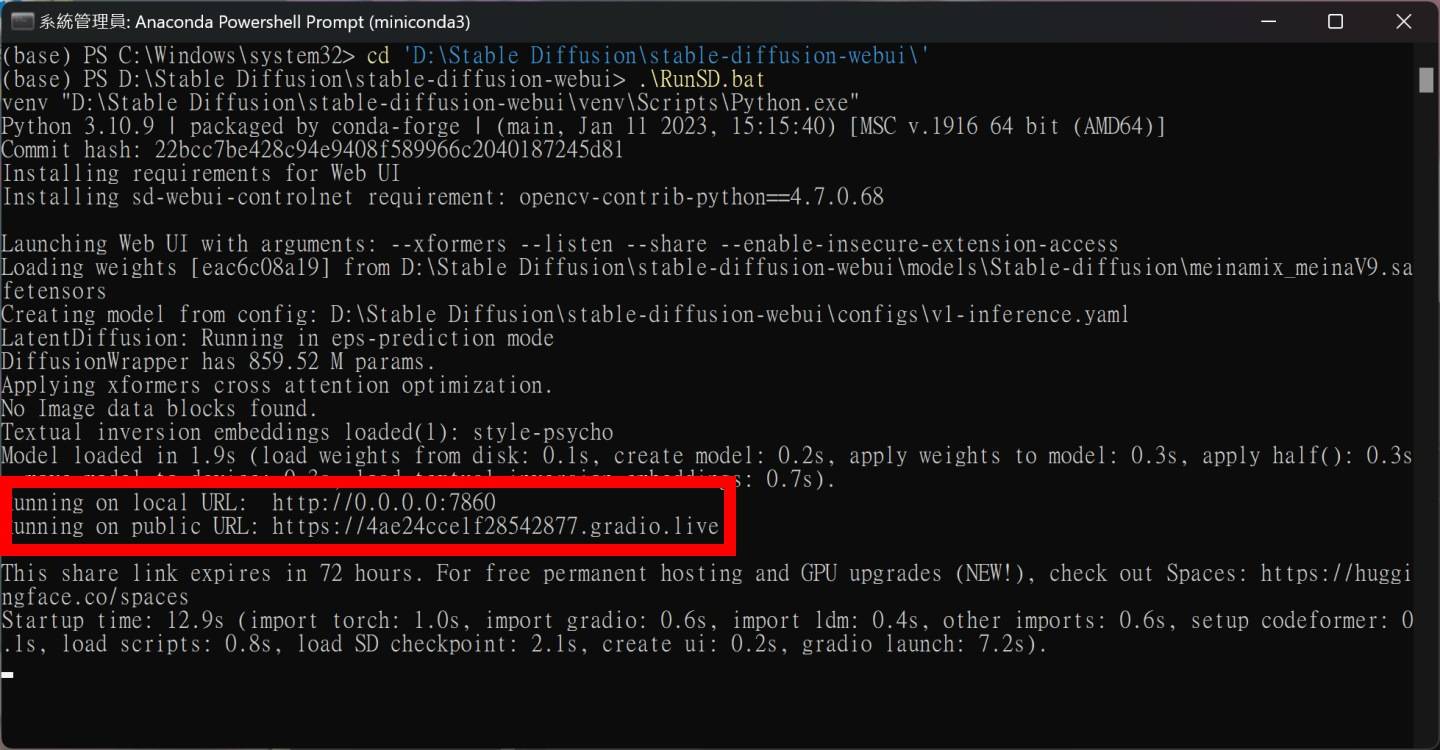 ▲ 接下来在跳出的窗口上点击鼠标右键,就会贴上指令并开启Stable Diffusion WebUI后台程序。
▲ 接下来在跳出的窗口上点击鼠标右键,就会贴上指令并开启Stable Diffusion WebUI后台程序。
 ▲ 接着在本机电脑浏览器的网址栏输入「127.0.0.1:7860」,就能连接到Stable Diffusion WebUI网页介面。
▲ 接着在本机电脑浏览器的网址栏输入「127.0.0.1:7860」,就能连接到Stable Diffusion WebUI网页介面。
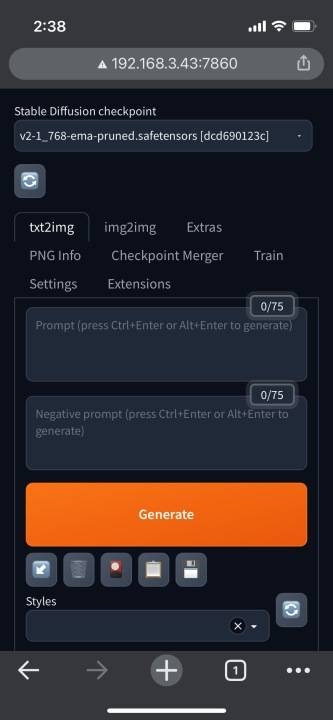 ▲ 只要设定正确,也可以从区域网络、外部网络的电脑或智能手机连入操作。 (图为使用智能手机于局域网连接)
▲ 只要设定正确,也可以从区域网络、外部网络的电脑或智能手机连入操作。 (图为使用智能手机于局域网连接)
▲操作流程的简易展示视频。
SD出击!
进入Stable Diffusion WebUI网页界面之后,可以在首页输入提示词(Prompt)并进行基本的参数设定,完成输入后点选「Generate」键就可以开始算图。
读者可以参考下方图片的接口说明,在正面提示词字段以英文输入想要在图片中出现的特征,而负面提示词则输入不想要的特征,设定区字段说明如下。
Stable Diffusion WebUI设定区字段说明
Sampling method:取样方式。 不同方式会稍微影响图片风格,笔者个人觉得Euler a、DPM++ 2M Karras、DPM++ SDE Karras效果都不错。 读者可以交互测试,找出不同模型最适合的方式。
Sampling steps:取样次数。 数值越高产生的图像越完整,但会降低算图速度。 建议设定30~50。
Restore faces:修正脸部。 如果生成的图片人物脸部异常,则可尝试勾选。
Tiling:拼接功能。 可以让输出的图片重复拼接。 可以在产生花纹时勾选。
Hires. fix:将输出图片通过特定算法或AI模型放大。
Width、Height:输出图片的长、宽分辨率。 过高的分辨率会降低速度并可能造成图像错误。 建议设定512~1024之间的数值。
Batch count:算图的批次数量。 建议可设定为10。
Batch size:每个批次的算图量。 单次工作的产生图片总数为Batch count成以Batch size。 建议可设定为1~3(即单次工作输出10~30张图片)。
CFG Scale:Classifier-Free Guidance Scale,分类器自由指示程度。 数值越高产生的图片特征会与提示词越接近,但过高的数值可能会让图像错误。 建议设定7~10之间。
Seed:乱数种子。 会影响图片的构图与细节,如果想要维持固定或临摹别人的构图,可以点击「回收」按钮或手动输入相同乱数并重新算图。 设定为-1则为随机乱数。
举例来说,在下方的图片中,笔者选择Anything V4.5 Checkpoint模型,搭配下列提示词与图片中的设定,就可以产出清新健康的图片。
正面提示词 :
(Masterpiece), ((2 girls)), running, (beach), sunshine
负面提示词:
(low quality:1.4), (worst quality:1.4), (monochrome:1.1),(bad_prompt_version2:0.8), bad-hands-5, lowres,(Bored pose), static pose, busty bad hands, lowers, long body, disfigured, ugly , cross eyed, squinting, grain, Deformed, blurry, bad anatomy, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, disgusting, poorly drawn, mutilated, ((text)), ((centered shot)), ((symetric pose)), ((symetric)), multiple views, multiple panels, blurry, multiple panels, blurry, watermark, letterbox, text,
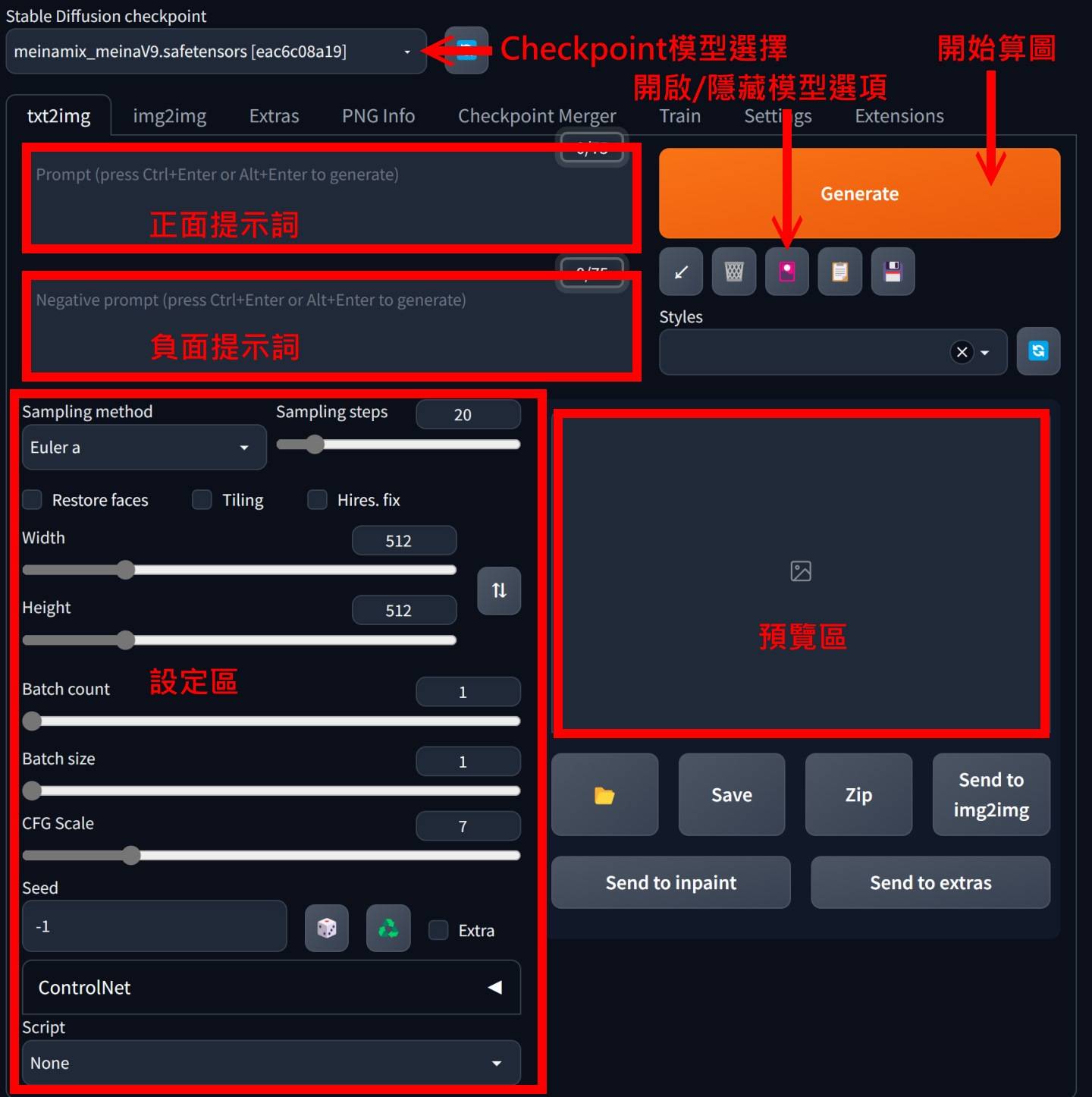 ▲ Stable Diffusion WebUI网页界面的各区说明。
▲ Stable Diffusion WebUI网页界面的各区说明。
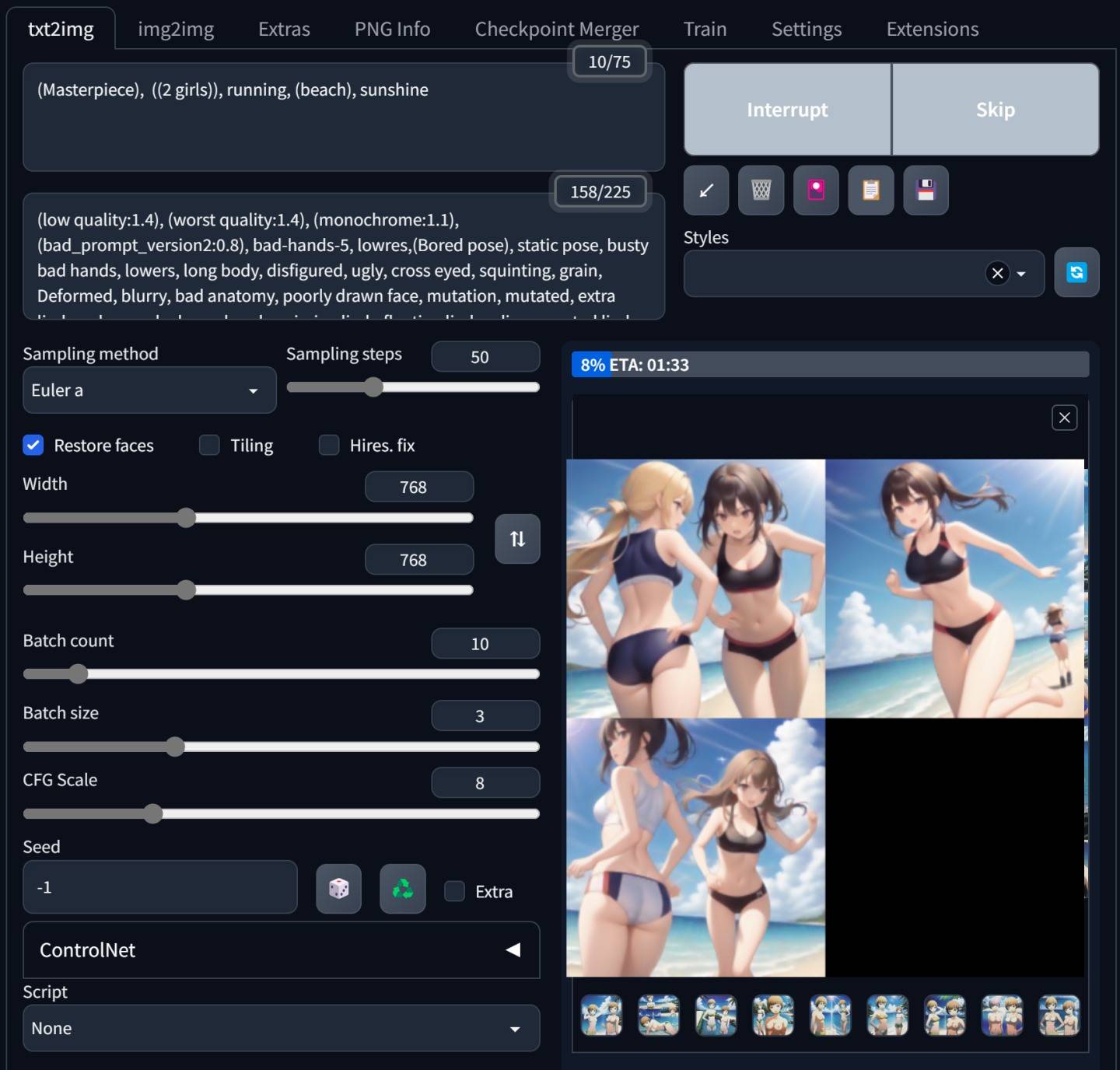 ▲ 输入提示词与基本设定后,点击「Generate」键就可以开始算图。
▲ 输入提示词与基本设定后,点击「Generate」键就可以开始算图。
 ▲ 你看,算出的图片是不是很清新健康呢。
▲ 你看,算出的图片是不是很清新健康呢。
或许读者也有所耳闻,「咒语」的好坏对产生图片的品质有很大的影响。 笔者将于下篇教学中,继续说明提示词的撰写技巧。
 微信扫一扫
微信扫一扫
相关推荐
-
怀旧游戏! 大宇资讯《明星志愿》系列上线Steam平台 3月31日发售
广受玩家们青睐的《明星志愿》系列单机游戏,即将上架Steam啦! 本次上架的作品,除了将一口气包含《明星志愿》、《明星志愿2》、《明星志愿2000》、《明星志愿闯通关》及《明星志愿…
-
iOS 17.0.1与iOS 16.7更新内容解析,三大安全漏洞遭修复
就在iPhone 15开卖当天,苹果再度向紧急替iPhone用户释出iOS 17.0.1和iOS 16.7更新,苹果只有在更新页面提到此提供重要的安全性修正,建议所有用户安装,实际…
-
《Call of Duty Warzone》手游版被证实在开发当中!正为手游制作招募人员!
早在去年 8月的时候,Activision 便公开表示他们已经设立了手游工作室,并正在开发一款《Call of Duty》手游。不过在近日,越来越多传言指 Activis…
-
《模拟市民4》新资料片《成长路上》正式公开
美商艺电和 Maxis于今(6)日公开《The Sims 4:成长路上》资料片,玩家将借由此资料片进入全新的城镇,且有机会透过不同的模拟市民动态与互动来探索家庭羁绊,见证模拟市民从…
-
《风起三国之乱世逐鹿》2023/11/24 最新礼包码序号兑换码,附领取攻略教学
《风起三国之乱世逐鹿》是一款史诗级的三国 IP 游戏,融合了次世代美术画面和策略元素,特色的沙盘战争玩法将带给玩家全新的三国体验,让你参与金戈铁马的战斗和策略博弈,战斗场景宏大且真…
-
iPhone 15 也可用旧配件 苹果推出 USB-C 至 Lightning 转换器
iPhone 15 系列换上 USB-C 接口接口后,不少用户担心过往的 Lightning 的配件怎样才可在新 iPhone 使用? 事实上,一些存储装置、外置麦克风是用 Lig…