


2022年,生成模型(Generative models)取得了巨大的进展。 不仅可以从自然语言提示中生成逼真的2D图像,也在合成视频和3D形状生成方面有着不俗的表现。
虽然目前的生成模型可以生成静态的 3D 对象,但合成动态场景更加复杂。 而且,由于目前缺少现成的4D模型集合(无论是有或没有文字注释),相比于2D图像和产生视频,由文字到4D的生成更加困难。
那么,如何基于简单的文字直接产生复杂的 3D 动态场景呢?
一种可能的方法是,从预先训练好的 2D 视频生成器开始,从产生的视频中提取 4D 重建。 然而,从视频中重建可变形物体的形状是一项非常具有挑战性的工作。
近日,来自Meta的研究团队结合视频和 3D 生成模型的优点,提出了一个新的文字到 4D(3D+时间)生成系统——MAV3D(Make-A-Video3D)。
据介绍,该方法使用 4D 动态神经辐射场(NeRF),通过查询基于文字到视频(T2V)的扩散模型,对场景外观、密度和运动一致性进行了优化。
同时,由特定文字生成的动态视频可以从任何摄影机位置和角度观看,并且可以合成到任何 3D 环境中。
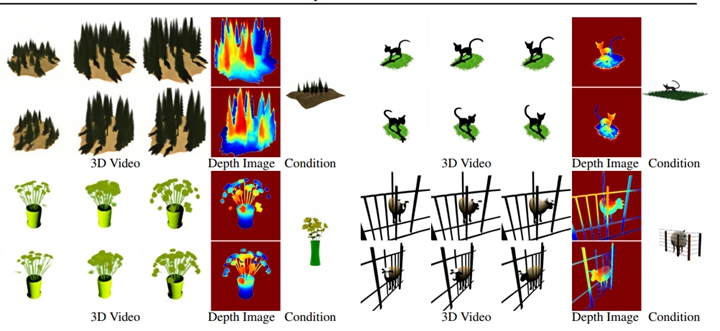
 ▲ 由MAV3D产生的样本。 行表示时间的变化,列表示视点的变化。 最后一列显示其相邻列的深度图像。
▲ 由MAV3D产生的样本。 行表示时间的变化,列表示视点的变化。 最后一列显示其相邻列的深度图像。
研究团队表示,MAV3D 是第一个基于文字描述产生3D动态场景的方法,可以为电玩游戏、视觉效果或AR/VR产生动画3D资产。 相关研究论文以「Text-To-4D Dynamic Scene Generation」为题,已发表在预印本网站 arXiv 上。
据论文描述,MAV3D 的实现不需要任何 3D 或 4D 资料,而且 T2V 模型也只是在文字-图像对和未标记的视频资料上训练的。
以往研究证明,仅仅使用视频生成器优化动态 NeRF 不会产生令人满意的结果。 为了实现由文字到 4D 的目标,必须克服以下 3 个挑战:
- 找到一个端到端、高效且可学习的动态 3D 场景的有效表示;
- 有一个监督来源,因为没有可供学习的大规模(文字,4D)数据集。
- 需要在空间和时间上缩放输出的分辨率,因为4D输出域是内存密集型的和运算密集型的。
那么,由简单的文字描述到复杂的 3D 动态场景生成,具体是如何实现的呢?
首先,研究团队仅充分利用了三个纯空间平面(绿色),算绘单个图像,并使用T2I模型运算 SDS 损失。
然后,他们添加了额外的三个平面(橙色,初始化为零以实现平滑过渡),算绘完整的视频,并使用T2V模型运算 SDS-T 损失。
最后,即超分辨率微调(SRFT)阶段,他们额外算绘了高分辨率视频,并将其作为输入传递给超分辨率元件。
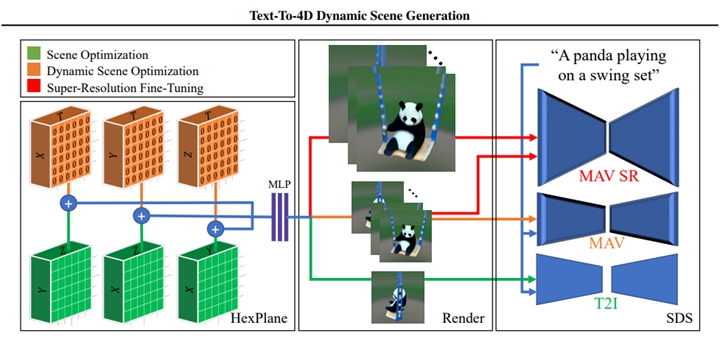 ▲ MAV3D 的实现路径
▲ MAV3D 的实现路径
另外,MAV3D 也可以完成由图像到 4D 应用的转换。 给定一个输入图像,通过提取它的 CLIP embedding,并以此来约束(condition)MAV3D。
 ▲ 图像到4D应用。
▲ 图像到4D应用。
然而,这一方法也存在一定的局限性。 例如,在实时应用中,将动态 NeRF 转换为不相交网格序列的效率很低。 研究团队认为,如果直接预测顶点的轨迹,或许可以改进。
此外,利用超分辨率信息已经提高了展示的质量,但对于更高细节的纹理还需要进一步改进。
最后,表示的质量取决于 T2V 模型从各种视图生成视频的能力。 虽然使用依赖于视图的提示有助于缓解多面问题,但进一步控制视频生成器将是有帮助的。
 微信扫一扫
微信扫一扫
相关推荐
-
漫画《灌篮高手完全版》电影上映纪念套书1/6帅气上市
尖端出版将于 2023 年 1 月 6 日推出《灌篮高手完全版》电影上映纪念套书,除了内容重新编排、校对,官方特别推出全新收藏书盒、限定书衣,加赠剧场版《灌篮高手 THE FIRS…
-
梦幻模拟战金骑士适合哪些英雄(梦幻模拟战中最好用的英雄)
在《梦幻模拟战手游》所有英雄的技能中,有一类”光环”性质的效果,每当敌军或者友军出现在自身范围几格范围内则会受到不同的效果。这类效果多见于一些英雄的被动技能…
-
《星空 Starfield》发售两周 玩家人数突破 1 千万人
《星空 Starfield》开发商BethesdaGame Studios20(1)日再宣布,该游戏玩家人数已突破1千万人。 《星空 Starfield》是一手打造《…
-
Epic Games《Snakebird Complete》一日限时免费,益智「贪食鸟」好评游戏
2023年结束倒数两天,Epic Games在今(30)日送出的是好评益智解谜游戏《Snakebird Complete》,时间只在12月30日一天之内,领取便可永久保存至Epic…
-
怎么赚钱快不用本钱一天500(如何才能实现呢)
其实互联网上不用本钱的赚钱方法还是蛮多的,想要赚钱快就一定要有一个好项目,最好做到精益求精的地步,才能让你在短时间之内达到月入过万。 目前我表弟就是在没本钱的情况下,用手机赚钱软件…
-
曝iPhone 17 Pro Max升级48MP长焦镜头!
根据最新的市场研究报告,Apple iPhone 17 Pro Max将配备高像素长焦镜头。分析师Jeff Pu在其报告中表示,Apple正在升级iPhone的…