
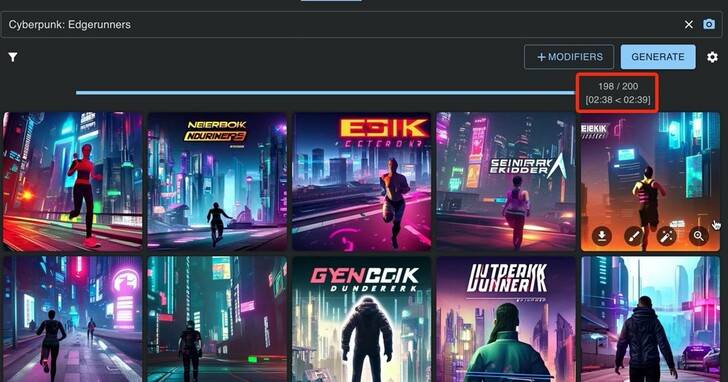

给AI一个关键词,一次画出200张图!
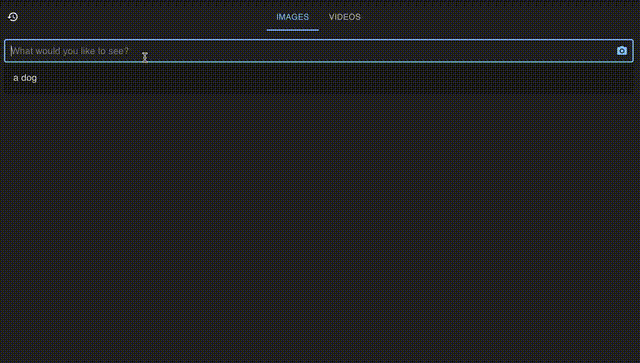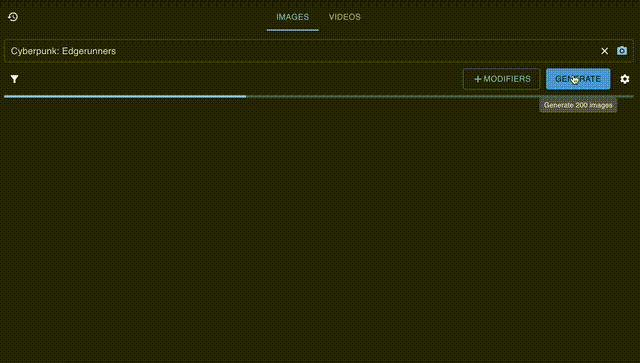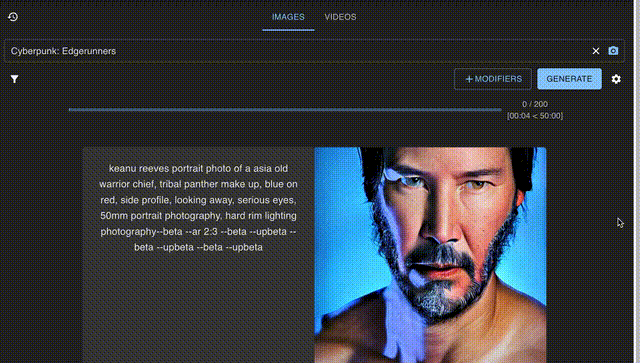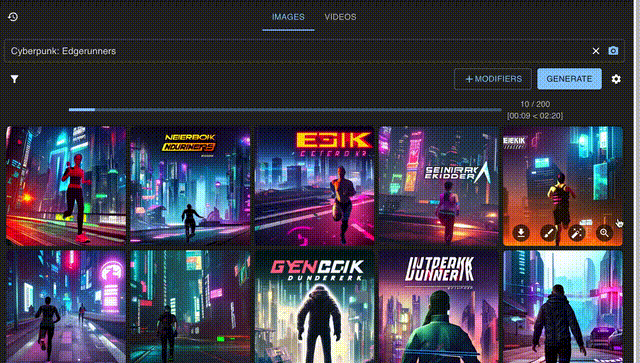
飞快作图速度,不到3分钟全搞定。
喜欢哪张任君挑选,还能直接二次调整编辑。

要知道,基础版Stable Diffusion默认一次只产生4张图片。 所以你可是得刷上许许多多次,才有可能得到一张稍微满意的画作时。
这就是新的Stableboost网站,一个新设计的Stable Diffusion互动界面。 它要做的事很简单,就是把Stable Diffusion的生产效率提高再提高。
而且,Stableboost免费使用的额度远比Stable Diffusion来得多。 每个月会有500分的免费额度使用。 超出额度之后每张图只收取1美分,仅为覆盖营运成本。 网站一经发表就引发各路网友围观。
这下子Stable Diffusion还真成了生产力工具。
同时,网站制作者的来头也不小:主要开发者是前特斯拉自动驾驶ML工程师。
还有特斯拉前高级AI主管安德烈·卡帕斯(Andrej Karpathy)提供建议给网站,他之前负责过的项目有特斯拉自动驾驶AutoPilot、特斯拉超算Dojo、特斯拉柯博文人形机器人……
所以这个网站到底能做什么?
超强操作界面
这个新出的AI画师最突出的一个特点就是可操作性强。
看它的设置界面,用户可以自定义设定的选项很多,包括图片数量、图片质量、尺寸……
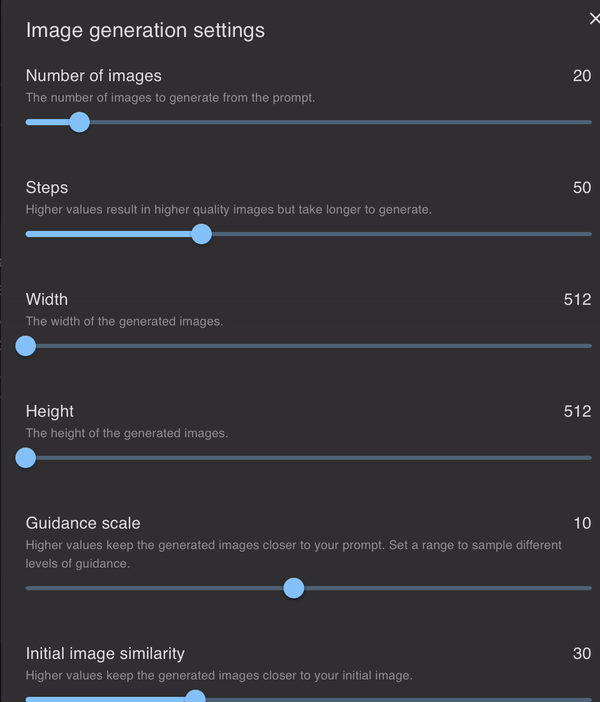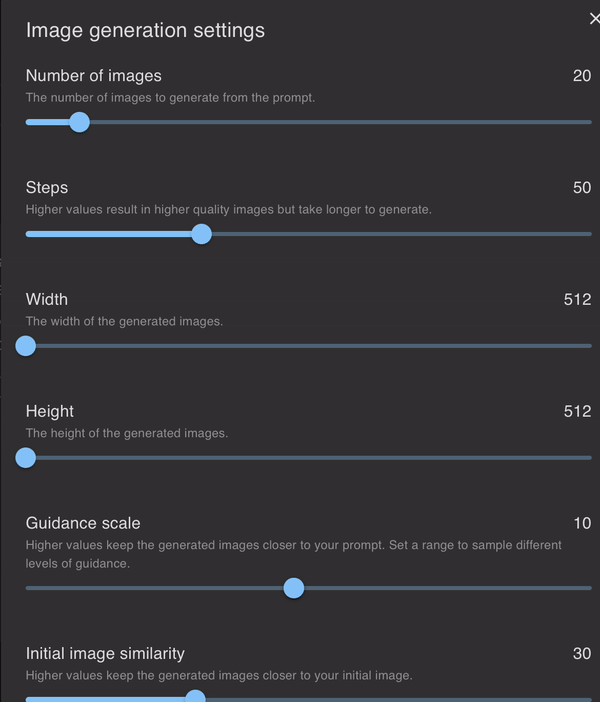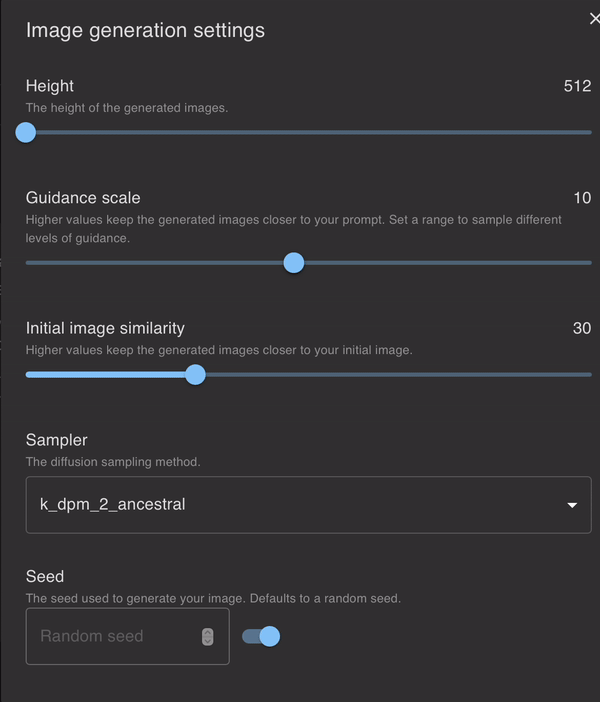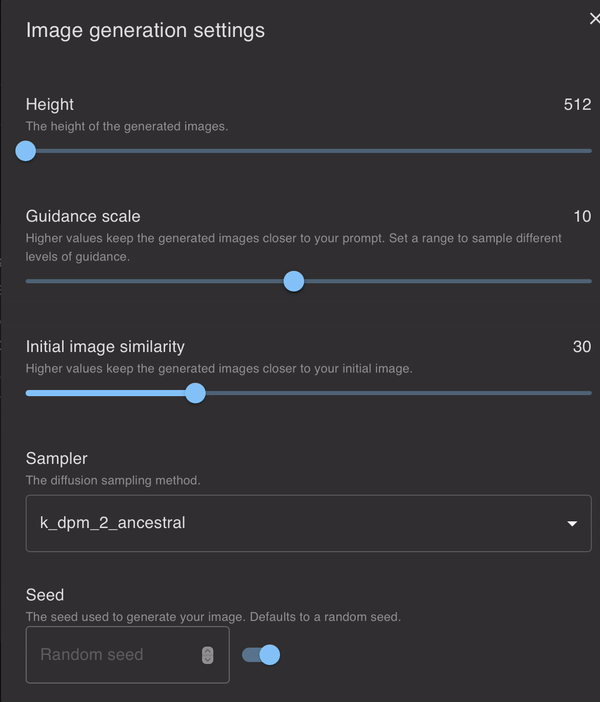
图片的数量可以从1~200之间任意选择,当然选择的数量越多,等得时间也就稍微久一丢。
要想设定产生的图片质量,可以滑动「Steps」和「Guidance scale」和调节。
图片的尺寸自然也不用多说,直接设置「高」和「宽」就可以了。
把这些相关的设定完成,就能安心地进行「创作」了。
和其他的AI一样,输入关键的提示词后,就能安心等待它产生的结果了。
不过要特别说明的是,Stableboost新增了个「修饰词」功能,就是说可以在原有的提示词上添加多个不同的修饰词,并且提示词可以和这些修饰词自由组合。
例如在输入一个提示词:小狗,修饰词可以设置为:森林、河边、夜晚。
最后产生的结果是这样的:
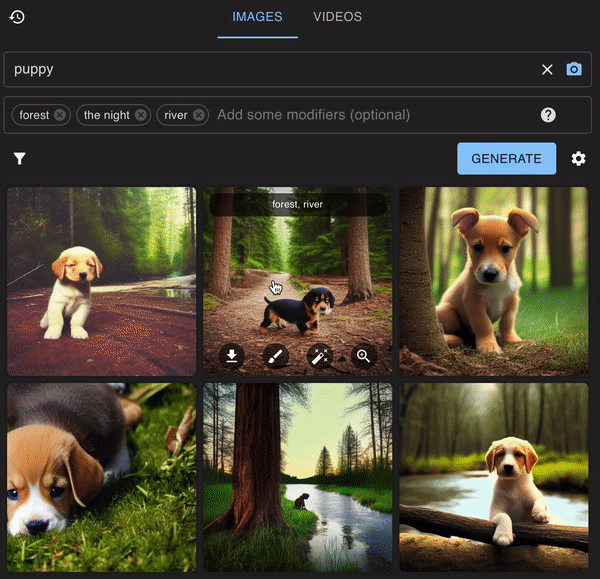
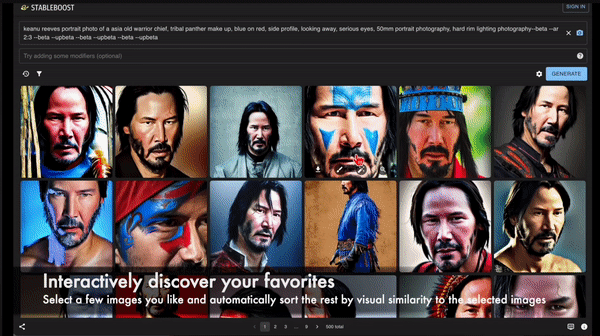
而且,为了更方便挑选图片,Stableboost还贴心地提供了筛选功能。
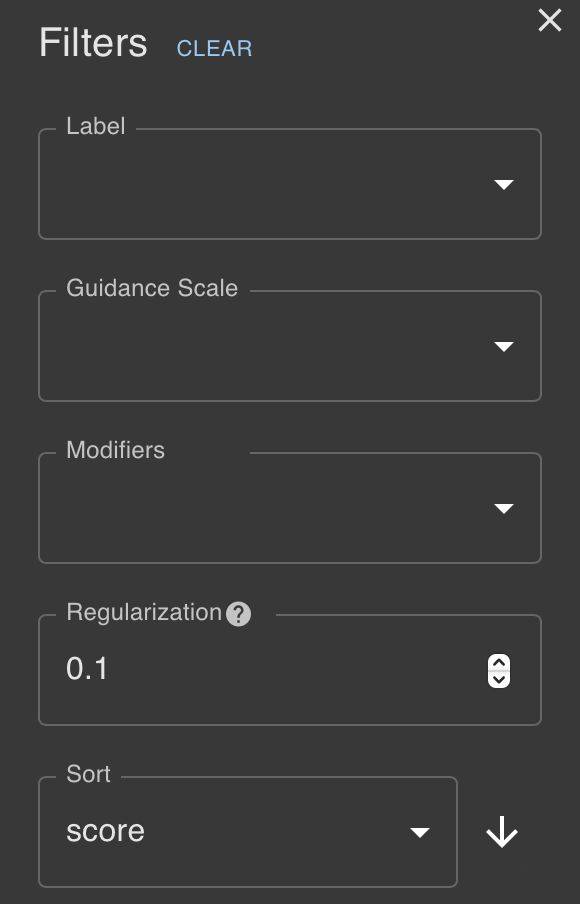
可以根据标签、图片质量、修饰词来筛选图片。
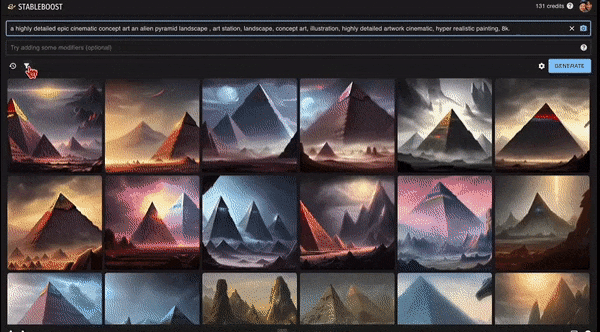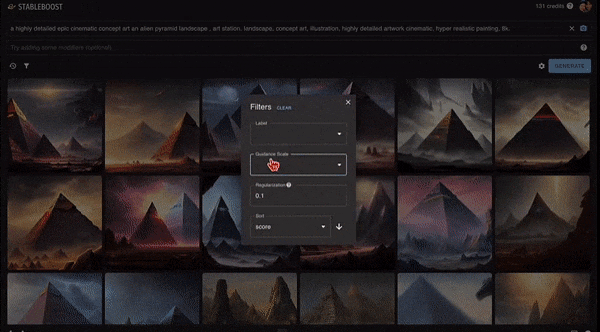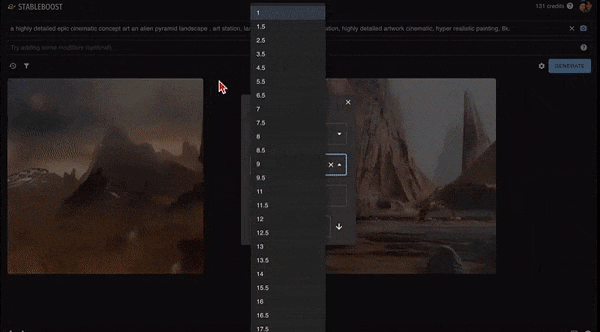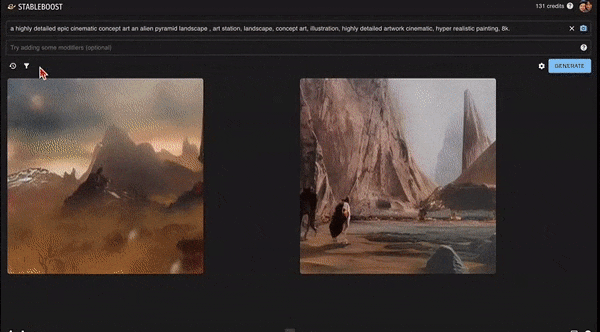
此外,它还能精益求精进行二次筛选,直接在上一步选出的图片上进行操作,点击图片右下的「放大镜」,可以进一步产生更多类似的图片。
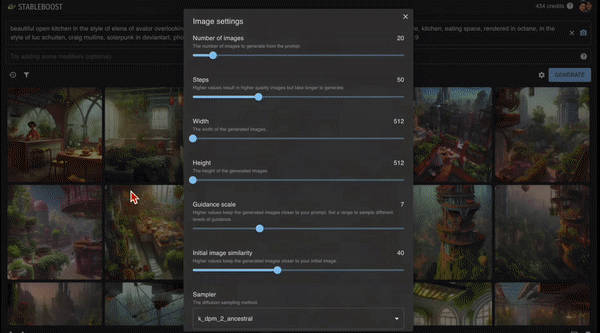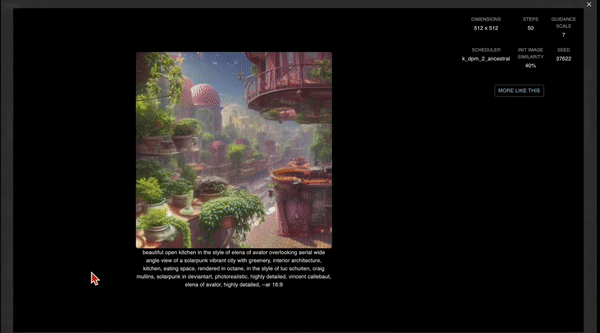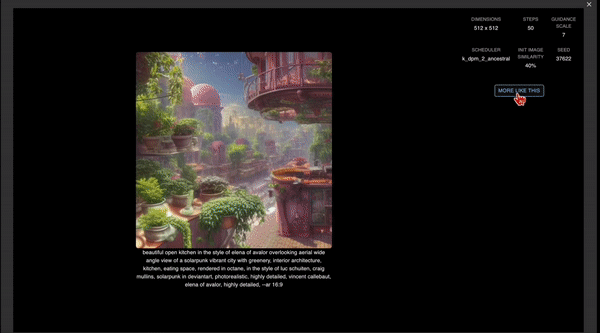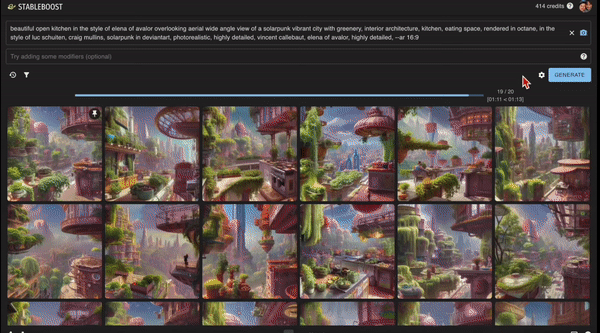
不过这个筛选方法都还只是前菜,Stableboost 这次「算法推荐」更聪明了。 用户只需要在产生的图片中点击自己最满意的那个,再点击右下角的「循环」按钮,这样Stableboost就会产生更多这种风格的图片。 并且,之后用户每点击一次图片,产生的结果都会不断变化。
另外,Stableboost还可以在原有图片上进行二次编辑,例如想为图片里的人物加上眼镜:

除了能产生图片外,Stableboost还可以产生视频,不过目前还比较初级,只是在不同提示词之间插入过渡的影格。
特斯拉前AI主管参与开发
体验了一轮之后,感觉Stableboost的运作还是非常顺畅。 有网友已经开始和作者许愿了:会不会加入Dreambooth呢?
DreamBooth 可是只需 3-5 张图片,加上文字表述,就能让指定物体搬移到其他场景或风格中去。
如果能all in one,AI作画的效率大概又会更上一层楼。 但如果检视一下这个网站的幕后团队,好像也不是完全不可能。
主要的开发者塔尔·施塔默(Tal Stramer),是资深AI工程师。 先后在推特、特斯拉、谷歌工作过。 今年6月他才结束了在特斯拉长达4年半的工作,离职前的职位是自动驾驶ML工程师。 另一位提供重要建议的,是前特斯拉高级AI主管安德烈·卡帕斯(Andrej Karpathy),他负责了几乎特斯拉所有明星项目:自动驾驶AutoPilot、超级电脑Dojo、柯博文人形机器人…… 是OpenAI的发起人之一。
今年7月,安德烈从特斯拉离职,连马斯克都罕见发推回应:感谢你为特斯拉所做的一切,与你共事是我的荣幸。

离职后,安德烈表示接下来还没有明确的工作去向,希望花更多时间在AI、开源和技术教育等方面的事情上。
的确,在他还博士班时,就亲自设计并主讲了一门名为 CS231n:用于视觉辨识的卷积神经网络的课程,成为斯坦福授课深度学习的讲师。
前几天他还做客了一档Podcast节目,和MIT人工智能专家Lex Fridman探讨了自动驾驶、人形机器人、AGI、特斯拉视觉方案等内容。

而从他这几个月的发推动向来看,他对AI画画很感兴趣。 于是,Stableboost就出现了。
▲ stableboost
 微信扫一扫
微信扫一扫
相关推荐
-
beanfun!漫画星推出新作《来补来坦来输出》以 MMO RPG 游戏为创作题材
beanfun! 漫画星近期携手新生代漫画家 waste 戊,推出全新原创台漫《来补来坦来输出》,以许多人熟悉的 MMO RPG 游戏世界为背景,剧情讲述暴力补师艾姆,在打副本的过…
-
《真人快打 11》怜悯怎么用?
真人快打11 玩家按住U键也就是切换正身反身姿势的键,然后连续按3次S键就是下蹲的键,然后松开U键,屏幕上会有金色的“Mercy”显示,就可以成功使用了。
-
苹果发表会 Apple Watch 8 规格、颜色、售价与上市日期总整理
苹果在今天的iPhone 14发布会上,推出了最新的Apple Watch Series 8(以下简称Apple Watch 8),整体外型与Apple Watch 7没有太大的差…
-
聆听海洋之声《我的美人鱼 -my Mermaid-》正式发表! 在手机中培育你的专属美人鱼
日本 Studio Sledgehammer 今(12)日公布了旗下新作育成手机游戏《我的美人鱼 -my Mermaid-(マイメード -my Mermaid-)》的制作消息与主要…
-
红警3盟军战役第一章(第三次世界大战的转折点)
正如将军所说,之后的苏军进攻强度异常的猛烈,入侵部队不仅有动员兵与战熊,携带有特斯拉线圈的电鳐也登上了布莱顿的海岸。 对于盟军来说,第三次世界大战的进程并不顺利,苏联在欧洲战场接连…
-
帝国时代3免费版(帝国时代3宣传片)
《帝国时代4》持续火热的同时,微软也没有放弃对老帝国的更新,《帝国时代3决定版》将在5月26日发布名为“地中海骑士”(Knights of the Mediterranean)的新…