
全新 Ada Lovelance 架构


NVIDIA正式发布全新GeForce RTX 4090显卡,采用全新AD102绘图核心、升级新一代AdaGPU微架构、CUDA Core增加至16,384个、第3代RT Core及第4代TensorCore、24GBGDDR6X容量,与上代架构相比光删化性能提升2倍、Ray Tracing性能提升4倍,并且在绝大部份游戏下4K 光追能够达至 100 FPS+,这么威猛的规格与性能值得硬件爱好者深入了解一下。
NVIDIA GeForce RTX 40 系列技术说明
目录
GeForce RTX 40 系列登场

NVIDIA 11 日正式发布首款 Ada Lovelance GPU 架构产品、核心代号为 AD102 的旗舰级 GeForce RTX 4090 显示卡,现代 GPU 图形运算技术不断提升,游戏画面的几何复杂性与光线运算技术皆大大提升,画面亦变得更加逼真,当 NVIDIA 发布 Turing GPU 架构时,Battlefield 5 仅为每个像素需要 39 次光线追踪操作来计算典型场景中的光照效果,但 4 年过后 Cyberpunk 的 RT:Overdrive 模式已经增至每像素推动超过 600 次光线追踪计算,因此需要更强大的 GPU 才能满足游戏的进步。
与之前的 Ampere GPU 架构相比,NVIDIA Ada Lovelance GPU 在光栅化游戏中的速度高达 2 倍,在光线追踪游戏中的速度高达 4 倍,是 NVIDIA 历史上最大的一代性能升级 (每一代都这样说 XD) ,主要得四大关键创新..
革命性的架构规模提升:
Ada Lovelance GPU架构规模大大提升,在制程创新下英伟达工程师能制造出具有763亿个晶体管、拥有高达18,432个CUDA Core芯片,并且能运作超过2.5GHz时脉以上,却可以保持与GeForce RTX 3090 Ti相同的450W TGP功耗表现。
更强大的 Ada Lovelance RT Core :
为了实现更强大的光线追踪能力,Ada Lovelance GPU架构升级第 3 代 RT Core 新增了两个硬件单元; Opacity Micromap Engine 可将经过 alpha 测试的几何体的光线追踪速度提升 2 倍,而 Displaced Micro-Mesh Engine 可实时产生 Displaced Micro-Triangles 以建立额外的几何体,能大大增加光线追踪的复杂却不会对 GPU 性能及储存造成负担。
着色器执行重新排序..
Ada Lovelance GPU架构的SM支持着色器执行重新排序,可以动态组织及重新排程着色器的工作负载,令光线追踪的着色效率大大提升,在Cyberpunk的RT:Overdrive模式中,性能相较上代SM提升44%。
NVIDIA DLSS 3 技术..
Ada Lovelance GPU架构新增DLSS 3技术,升级第4代Tensor Cores新增全新的光流加速器能提供AI画帧生成功能,可将DLSS 3的帧速率提升至之前的DLSS 2.0的2倍,同时保持或超过原生图像质量,并且新增FP8张量运算能力,与传统的蛮力图形渲染相比,DLSS 3最终速度提高了4倍,同时提供了低系统延迟。

NVIDIA 11日将会正式发布GeForce RTX 4090型号,基于AD102绘图核心、拥有16,384个CUDA Cores、24GBGDDR6X容量,MSRP定价NT$ 56,990,能够在大部份4K+RT启动下提供100FPS+游戏性能。
紧接 11 月会将会再发布 2 款 GeForce RTX 4080 型号,RTX 4080 12GB 基于 AD104 绘图核心,拥有 7,680 个 CUDA Cores、12GB GDDR6X内存,RTX 4080 16GB基于AD103绘图核心,拥有9,728个CUDA Cores、16GBGDDR6X内存,MSRP售价分别为NT$ 32,990与NT$ 42,990。
TSMC 4N制程、NVIDIA AD102绘图核心
NVIDIA AD102 绘图核心基于全新 Ada Lovelance 微架构,并用于 GeForce RTX 4090 产品之中,性能提升主要来自 FP32 运算单元数目及时脉倍增,更大的 L2 快取容量及全新着色器执行排序技术,升级第 3 代 RT Cores、升级第 4 代 Tensor Cores,与上代比较 Ampere GPU 微架构比较,传统光栅图形运算提高了 2 倍 ,同时在光线追踪性能上提升近 4 倍。
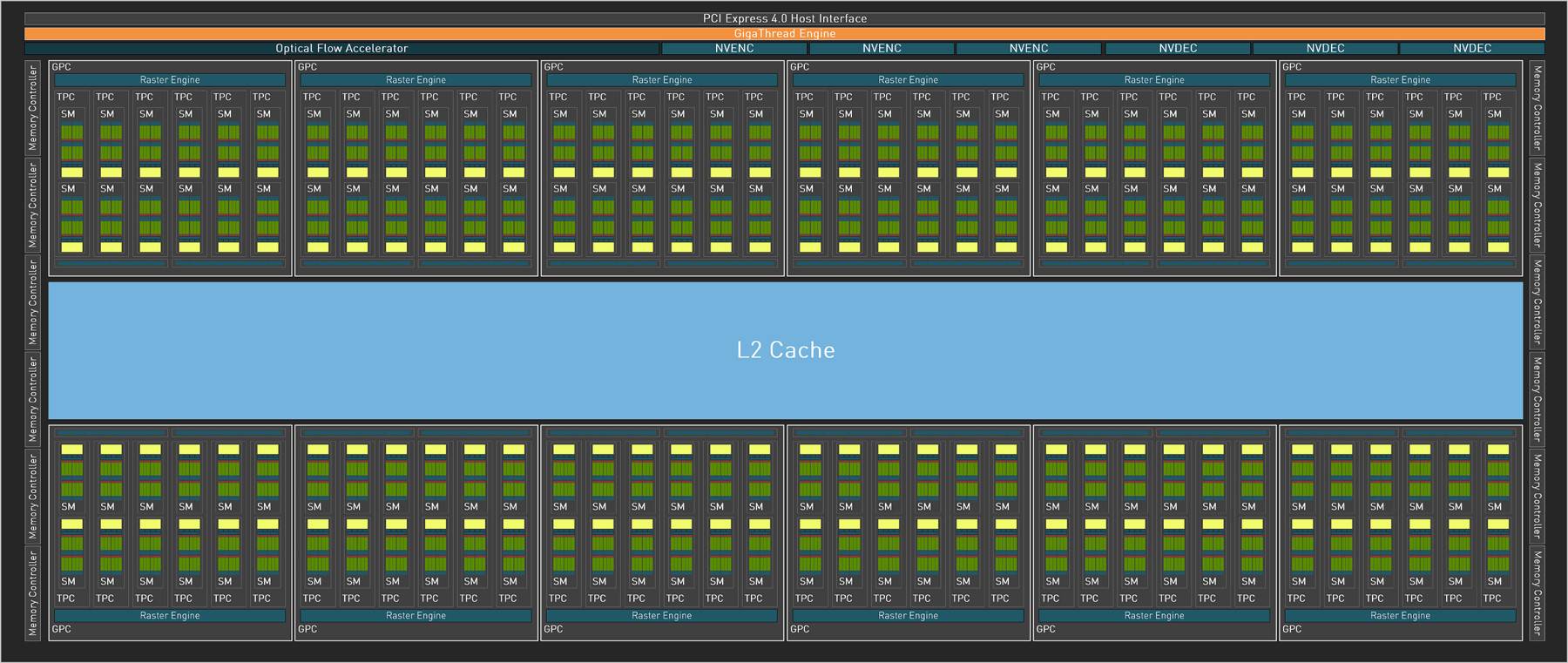
GeForce RTX 4090 采用 AD102-300 绘图核心,采用 TSMC 4N NVIDIA Custom 制程,拥有 763 亿个电晶体、 Die Size 608.5mm² 相较上代 GA102 的 628mm² 还要小,完整的 AD102 芯片内建 12 个 GPC 单元、72 个 TPC 纹理处理群集及 144 个 SM 串流多处理器,增至 18432 个 CUDA Cores、 144 个 RT Cores 及 336 个 Tensor Cores。

不过,GeForce RTX 4090部份单元作出了屏蔽,删减至只有11个GPC单元、64个TPC纹理处理群集及128个SM串流多媒体处理器,具备16,384个CUDA Cores、128个RT Cores及512个Tensor Cores。
核心时脉方面,虽然芯片规模大幅提升但时脉仍然保持于超高水平,GeForce RTX 4090默认时脉2.23GHz、Boost时脉为2.52GHz,最高TGP为450W。
此外,GeForce RTX 4090采用21Gbps GDDR6X内存,384-bit内存接口总带宽为1008GB/s,更重要是L2快取容量大幅增加至73,732KB,相较AMD的Infinity Cache作为L3 Cache拥有更高效率,能大幅升游戏Workload数据命中率,降低读取延迟达并减少GDDR6X内存频宽使用。
| Founders Edition | RTX 4080 12G | RTX 4080 16G | RTX 4090 |
|---|---|---|---|
| GPU Codename | AD104 | AD103 | AD102 |
| GPU Architecture | NVIDIA AdaLovelance | NVIDIA AdaLovelance | NVIDIA AdaLovelance |
| GPCs | 5 | 7 | 11 |
| TPCs | 30 | 38 | 64 |
| SMs | 60 | 76 | 128 |
| CUDA Cores / SM | 128 | 128 | 128 |
| CUDA Cores / GPU | 7680 | 9728 | 16384 |
| Tensor Cores / SM | 4 (4th Gen) | 4 (4th Gen) | 4 (4th Gen) |
| Tensor Cores / GPU | 240 (4th Gen) | 304 (4th Gen) | 512 (4th Gen) |
| RT Cores | 60 (3rd Gen) | 76 (3rd Gen) | 128 (3rd Gen) |
| GPU Boost Clock (MHz) | 2610 | 2505 | 2520 |
| Peak FP32 TFLOPS (non-Tensor) | 40.1 | 48.7 | 82.6 |
| Peak FP16 TFLOPS (non-Tensor) | 40.1 | 48.7 | 82.6 |
| Peak BF16 TFLOPS (non-Tensor) | 40.1 | 48.7 | 82.6 |
| Peak INT32 TOPS (non-Tensor) | 10.6 | 24.4 | 41.3 |
| RT TFLOPS | 92.7 | 112.7 | 191 |
| Peak FP8 Tensor TFLOPS with FP16 Accumulate | 320.7/641.4 | 389.9/779.8 | 660.6/1321.2 |
| Peak FP8 Tensor TFLOPS with FP32 Accumulate | 320.7/641.4 | 389.9/779.8 | 660.6/1321.2 |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate | 160.4/320.8 | 194.9/389.8 | 330.3/660.6 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate | 80.2/160.4 | 97.5/195 | 165.2/330.4 |
| Peak BF16 Tensor TFLOPS | 80.2/160.4 | 97.5/195 | 165.2/330.4 |
| Peak TF32 Tensor TFLOPS | 40.1/80.2 | 48.7/97.4 | 82.6/165.2 |
| Peak INT8 Tensor TOPS | 320.7/641.4 | 389.9/779.82 | 660.6/1321.2 |
| Peak INT4 Tensor TOPS | 641.4/1282.8 | 779.8/1559.6 | 1321.2/2642.4 |
| Frame Buffer Memory Size and Type | 12GB GDDR6X | 16GB GDDR6X | 24GB GDDR6X |
| Memory Interface | 192-bit | 256-bit | 384-bit |
| Memory Clock (Data Rate) | 21 Gbps | 22.4 Gbps | 21 Gbps |
| Memory Bandwidth | 504 GB/sec | 716.8 GB/sec | 1008 GB/sec |
| ROPs | 80 | 112 | 176 |
| Pixel Fill-rate (Gigapixels/sec) | 208.8 | 280.6 | 443.5 |
| Texture Units | 240 | 304 | 512 |
| Texel Fill-rate (Gigatexels/sec) | 626.4 | 761.5 | 1290.2 |
| L1 Data Cache/SharedMemory | 7680 KB | 9728 KB | 16384 KB |
| L2 Cache | 49152 KB | 65536 KB | 73728 KB |
| Register File Size | 15360 KB | 19456 KB | 32768 KB |
| Video Engines | 2x NVENC (Gen8) | 2x NVENC (Gen 8) | 2x NVENC (Gen 8) |
| 1x NVDEC (Gen5) | 1x NVDEC (Gen5) | 1X NVDEC (Gen 5) | |
| TGP Power | 285W | 320W | 450W |
| Transistor Count | 35.8 Billion | 45.9 Billion | 76.3 Billion |
| Die Size | 294.5mm² | 378.6mm² | 608.5mm² |
| Manufacturing Process | TSMC 4N | TSMC 4N | TSMC 4N |
| PCIe Interface | Gen4 | Gen4 | Gen 4 |
经改良的 Ada Lovelance 架构
GPC 是 NVIDIA GPU 中最顶层的硬件区块,所有关键图形处理单元都位于 GPC 中。 Ada Lovelace 每个 GPC 包括 1 个专用的光栅引擎、 2 个光栅操作 (ROP) 分区,每个分区包含 8 个单独的 ROP 单元和 6 个 TPC,每个 TPC 包括 1 个 PolyMorph 引擎和 2 个 SM。
AD102 GPU 中的每个 SM 包含 128 个 CUDA Core、 1 个 Ada Lovelace 第三代 RT 核心、4 个 Ada Lovelace 第四代 Tensor Cores、4 个 Texture 纹理单元、 1 个 256 KB 文件暂存器和 128 KB 的 L1 / 共享内存,可根据图形或计算工作负载需求分配成不同的内存大小。
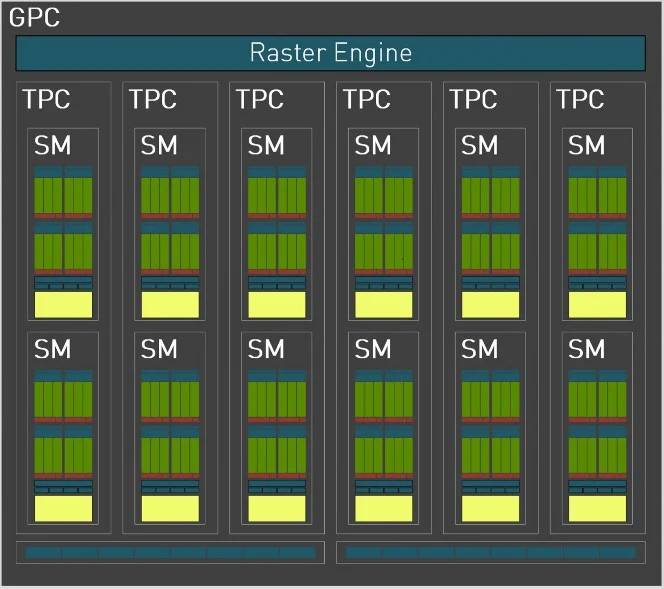
与 Ampere GPU 一样,AD102 的SM 单元分为4个分区,每个分区包含1个64 KB文件暂存器、一个L0指令缓存、一个 warp调度程序、一个调度单元、16个专用于处理FP32的CUDA核心操作,每个周期最多可处理16个FP32操作,16个可以处理FP32或INT32操作的CUDA核心,每个周期16个FP32操作或每个时钟16个 INT32 操作, 4 个加载 / 存储单元,以及执行超越和图形插值指令的特殊功能的 SFU 单元,除了换上第 4 代的 Tensor Core 设计,FP 单元在微架构上并没有太大变动。
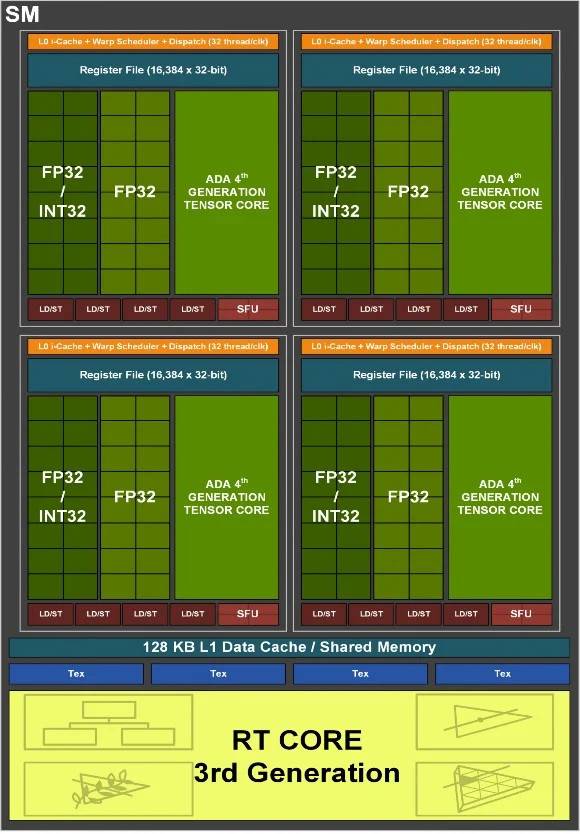
与上代 Ampere GPU 相比,Ada Lovelace GPU 的 L2 快取进行了彻底改造,完整的 AD102 GPU 拥有高达 98304 KB 的 L2 快取,比 GA102 中的 6144 KB 提高了 16 倍,所有应用程序都将受益于拥有如此庞大、更高速的 L2 快取,例如 Ray Tracing 光线追踪当中的路径追踪之类的复杂操作将产生最大的好处,相较 AMD 的 Infinity Cache 作为 L3 缓存拥有更高效率,能大幅升游戏 Workload 数据命中率,降低读取延迟达并减少 GDDR6X 内存带宽使用。
此外,AD102 GPU受惠于TSMC 4N制程,在NVIDIA工程师与TSMC密切合作下令AD102能包含更多的运算核心,AD102包含的CUDA核心比上一代GA102GPU多70%,拥有高达763亿个晶体管,并且关键路径中使用高速晶体管设计,令AD102 GPU时脉可运作于2.5GHz甚至更高,并且提供了出色的能耗比,对比RTX 3090 Ti GPU在相同功耗运作时,RTX 4090 GPU可以提供接近2倍的性能表现,如果启用DLSS 3技术后甚至最高可达4倍。
升级第3代Ray Tracing引擎
Ray Tracing 光线追踪技术是一种密集型渲染技术,可以逼真地模拟场景及对象的光线,即时以物理方式渲染正确的反射、折射、阴影及间接照明效果。 过去的GPU架构并无法对游戏及图形进行复杂的实时光线追踪处理,NVIDIA 经过过10年的研究及开发,终于在上代GeForce RTX 20的「Turing」GPU微架构中加入硬件光线追踪加速引擎 —「RT Cores」,结合NVIDIA RTX软件引擎,实现逼真的实时光线场景效果。
到了GeForce RTX 30系列的 Ampere GPU 升级了第2代的RT Cores,BVH遍历与射线三角交测运算能力提升了2倍,第1代Turning SM在Ray Tracing运算时不能同时执行绘图或运算,到了 Ampere SM 强化了异步运算能力,当执行Ray Tracing 运算时可同步进行绘图或运算,令Ray Tracing 的游戏执行效率大大提升。

来到 GeForce RTX 40 的 Ada Lovelace GPU 升级至第 3 代 RT Cores,它的 Triangle Intersection Engine 相较上代快 2 倍的 Ray-Triangle 相交吞吐量,能为游戏场景中加入更多细节,同时有快 2 倍的 Alpha Traversal 处理能力,新增 Opacity Micromap Engine 直接对几何物件进行 alpha 测试,并显著减少基于着色器的 alpha 运算量。

在 Ada Lovelace GPU 之前,当光线扭曲投射到不同程度透明级别的对象时,例如叶子或火焰等复杂形状通常使用纹素的 alpha 通道来表示,单个光线运算也可能需要多次着色器调用才能完成,即使光线只是简单地表征为命中或未命中都需要大量的运算成本。
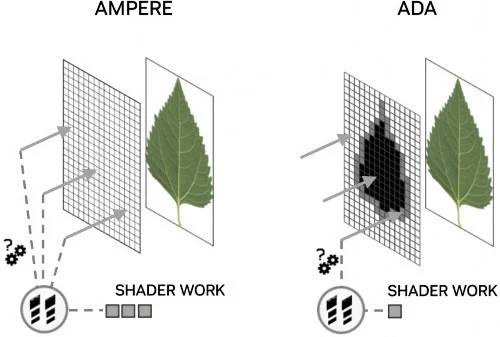
为了更有效处理此类内容,NVIDIA工程师在第3代RT Core中增加了Opacity Micromap Engine,为非不透明对象产生微三角形的虚拟网格,每个微三角形都具有不透明状态,RT Core使用该状态直接解析与非透明三角形的光线交叉点,令Alpha场景遍历性能大幅提升,性能升幅很大程度取决于使用情况,如果场景出现大量投射在 alpha 测试几何体上的阴影光线时会看到最大的收益。

第 3 代 RT Core 另一个重要提升是添加 Displaced Micro-Mesh Engine,通过将几何结构换置成微网格,利用 LOD 细节层进行光栅化,相较使用传统三角几何光线追踪处理,不仅拥有更多细节,相较上代 BVH 数据构建速提升了 10 倍, BVH 所需资料容量减少了 20 倍,而且对复杂环境进行光线追踪时,追踪成本缓慢增加,几何增加 100 倍可能只会增加 1 倍追踪时间。
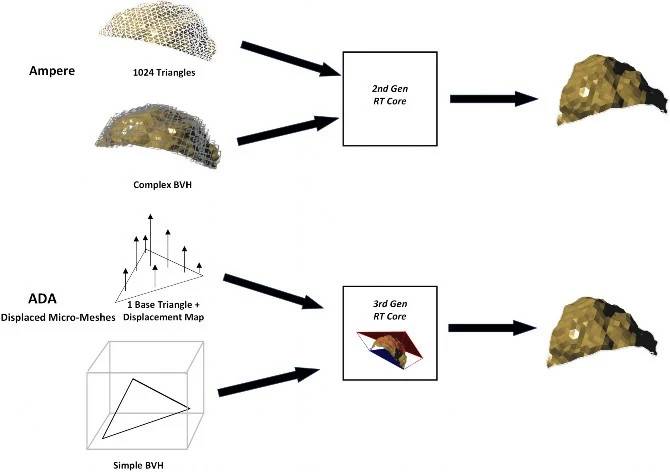
上代 Ampere GPU 可能需要 1024 个三角几何与复杂的 BVH 结构进行的光线追踪,同样的效果通过 Displaced Micro-Mesh Engine,只需要 1 个基础三角形和 1个更换贴图定义及简单的 BVH 结构就能完成,可以在不相应增加处理时间或内存消耗的情况下实现丰富度的数量级增加。
Shader Execution Reording 技术
为实现游戏实时光线追踪的逼真渲染,运算时增加了大量的环境中模拟光线运动,同时亦意味着GPU原始处理工作量变得越来越不连贯。 例如,用于反射、间接照明和半透明效果的二次光线往往会射入,不同的方向并击中不同的材质,导致二次击中着色器的有序性和效率较低,不规律性的运算会导致GPU的处理单元 SM 的低效使用,因此 NVIDIA 在 Ada Lovelace GPU 架构中加入 Shader Execution Reording 着色器执行重新排序技术, 它可以动态地重新排序着色工作以实现更好的执行效率。
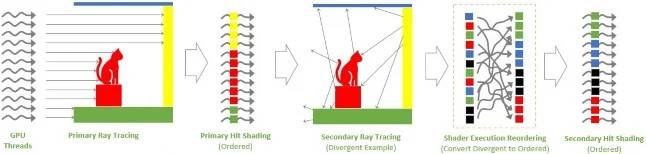
透过Shader Execution Reording技术,着色器执行重排序时在光线追踪管道中添加了一个新阶段,该阶段对二次命中着色进行重新排序和分组,以具有更好地执行局部性,在Cyperpunk 2077 RT: Overdrive 模式下,启动ShaderExecution Reording技术后性能提升高达44%,相当惊人。
升级第 4 代 Tensor Cores、全新 DLSS 3 技术
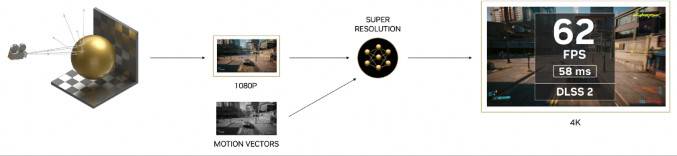
Tensor Cores 是专门为在 AI 和 HPC 应用程序中使用的矩阵乘法和累加数学运算量身定制的高性能运算,可以用于为矩阵计算提供了突破性的性能,这对于深度学习神经网络训练和边缘发生的推理针对游戏应用层面,Tensor Cores 其中一个重点就是加入全新 DLSS 深度学习超级采样技术,通过深度神经网络提取渲染场景的多维特征, 并智能地组合来自多个帧的细节,以构建高质量 3D 影像。 与传统的 AA 技术相比,DLSS 使用更少的输入样本,同时避免了透明度和其他复杂场景元素的算法难度。

全新 Ada Lovelace GPU 微架构升级至第 4 代 Tensor Cores 运算单元,相较上代在 FP16、BF16、TF32、INT8 和 INT4 性能提升2 倍以上,新增 FP8 运算能力 AD102 可提供超过 1.3 PetaFLOPS 的张量处理,并且升级至 DLSS 3 技术能透过深度学习使用 AI 生成整帧以大幅提升性能。
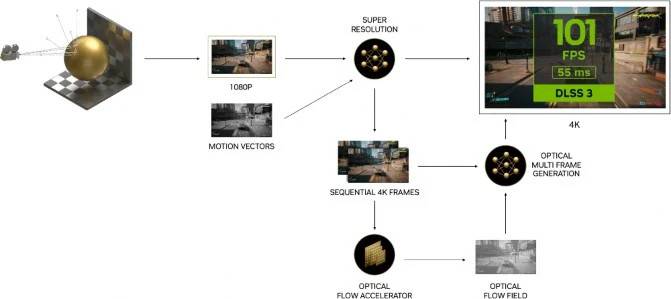
DLSS 3 技术是将先前DLSS 2技术,通过Tensor Cores运动矢量运算与超分辨率技术下,在帧与帧之间加插由以AI运算生成的新帧,启用DLSS 3后,AI将使用DLSS超分辨率重建第一帧的3/4,并使用DLSS AI帧生成重建整个第二帧,因此DLSS 3重建了总显示像素的7/8,因此显著提高了性能。
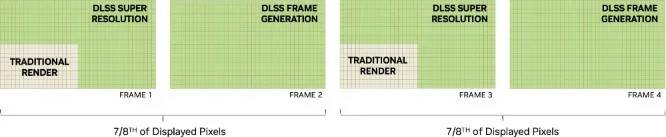
为了令 AI 帧成生的图像不会出现重影、卡顿和模糊等伪影, ADA Lovelace GPU 新增 Optical Flow Accelerator 光流加速器,它能捕获粒子、反射、阴影和照明等信息,DLSS 3 可以计算场景中的一切是如何从一个像素移动到另一个像素的,令游戏画面不会出现异常重建。

更重要的是 DLSS 3 可以减低 CPU 造成的性能瓶颈,一些需要 CPU 物理模拟的游戏例如 Microsoft Flight Simulator (微软模拟飞行),对于 CPU 的性能要求十分高,因此 GPU 经常处于空闲状态等待指令,DLSS 3 可以将 CPU 密集型游戏转换为 GPU 密集型游戏,因为在 AI 生成帧中全由 GPU 负责,因此在执行 CPU 受限的游戏, 例如那些需要大量物理或涉及大型开放世界的游戏, GeForce RTX 40 系列显卡在相同 CPU 运算能力下,帧速率高达两倍的帧速率进行渲染。
升级第 8 代 NVENC 编码引擎
为提升GPU编辑性能,NVIDIA AD102 GPU配搭了两个第8代NVENC编码器,上代 Ampere GPU只提供AV1解码支持,Ada Lovelace新增AV1编码支持能力,其编码效率相较H.264编码器提升了40%,可支持8K/60 HDR或是同时为4个4K/60 HDR视频编码运算。
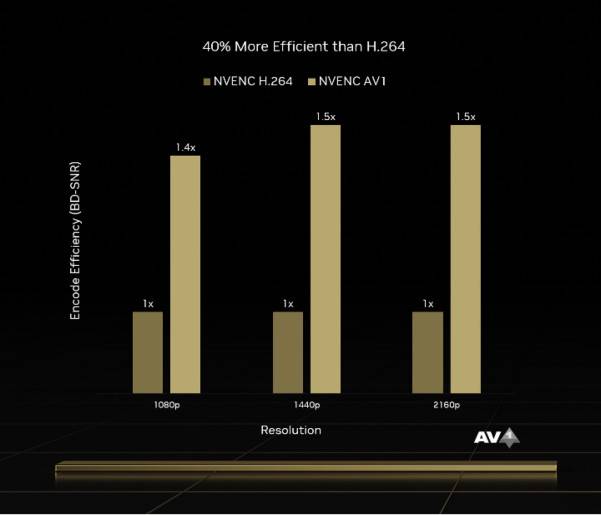
解码器方面,NVIDIA AD102 GPU 与上代一样拥有 1 个第 5 代 NVDEC 解码器,支持 MPEG-2、VC-1、H.264 (AVCHD)、H.265 (HEVC)、VP8、VP9 和 AV1 视频格式的硬件加速视频解码,支持 8K/60 分辨率。
NVIDIA GeForce RTX 4090 Founder Edition 外观简介



收到由 NVIDIA 送测的 GeForce RTX 4090 Founder Edition 显示卡,外观设计与上代 GeForce RTX 3090 Ti 相似,只有少许细节上的差异,例如金属外框向内微凹,使用的字体亦有所改动,上手后可以感受到 NVIDIA 对细节的重视,卡的正面都是雾黑色的散热鳍片,边缘采用钛金色铝金属框架,并且印有 RTX 4090 字样, 沿用轴向式散热设计,正反两面各有一个12cm散热风扇,能够将部份废热排向CPU区域及直接排出机壳,令机壳内部温度变得更平均。

GeForce RTX 4090 Founder Edition 相较 RTX 3090 Ti 更庞大,尺寸为 304mm x 137mm x 61mm 根本上小机壳都可以直接略过,用上 Triple Slot 散热器、双 12cm 轴向式散热风扇,顶端 GeForce RTX 字样在运作时会透出白色 LED 灯效,可惜不是 RGB 灯效。

考虑到大部份人安装显卡后,从机壳外看进去只会看到卡背,NVIDIA 将设计反转,把背板变成正面,并显示着「RTX 4090」字样,整张卡所有螺丝孔都用磁吸隐藏了,NVIDIA 真的是从用户的角度、在细节中作出了考量,难怪那么多玩家想买 Founder Edition。
NVIDIA PG136D 公板设计
拆开散热器后,以看到它采用PG136D公板设计,与RTX 3090 TiPCB布局非常相似,NVIDIA刻意将电路板尽量缩小,让卡身可以镂空,让轴向式风扇将带气流带到CPU区域,12 Layers PCB设计并经过低阻抗提供讯号及电力传输优化,同时保留了不俗的超频性能。


供电设计方面,升级至23相Dual FET供电模组设计,其中20相负责GPU供电、3相负责GDDR6X供电,采用Monolithic Power Systems MP2891VRM控制芯片配搭Monolithic Power Systems MP86957 70A DrMOS芯片。
NVIDIA AD102-300 绘图核心
NVIDIA GeForce RTX 4090 Ti 采用了经删减后的 AD102-300 绘图核心,采用 TSMC 4N 制程、拥有 763 亿个晶体管、Die Size 约为 608.5mm²,部份单元作出了遮蔽,删减至只有11个GPC单、64个TPC纹理处理群集及128个SM串流多媒体处理器,具备16,384个CUDA Cores、128个RT Cores及 512 个 Tensor Cores。

核心时脉方面,虽然芯片规模大幅提升但受惠于TSMC 4N制程,GPU时脉相较上代大幅提升,GeForce RTX 4090 FE预设为2.23GHz基础时脉、2.52MHz加速时脉,支持GPU Boost 4.0技术可因应负载自动超频至更高时脉,最高TGP为450W与RTX 3090 Ti相同。
384-bit 24GB GDDR6X 内存容量
记忆体方面,GeForce RTX 4090具备24GBGDDR6X内存容量及384-bit内存控制器,存储器带宽由448GB/s提升至高达1008GB/s (1TB/s),再加上更高的74MB L2快取容量,以满足更高分辨率、更复杂的着色器渲染运算画面。

采用了12 颗 Micron D8BZC GDDR6X 颗粒编号,为 MT61K512M32KPA-21:U 并支持 ECC 功能,每颗单颗容量为 16Gbit (2GB),总供 24GB 显示内存容量,采用单面 24GB GDDR6X 内存配置,可避免 RTX 3090 双面 24GB GDDR6X 内存配置的背面内存颗粒过热问题,在 NVIDIA Control Panel 程序中,使用者可以看到 GeForce RTX 4090 能支持 NVIDIA Quadro / Tesla 系列专业绘图卡才能拥有的 ECC 功能。
Triple Slot 轴向式散热器设计
NVIDIA GeForce RTX 4090 FE沿用轴向式散热设计,设计与RTX 3090 Ti相同只是变得更巨型了,Triple Slot双12cm风扇,GPU /VRM及GDDR6X内存位置被巨型VaporChamber均热板覆盖,再透过6支导热管传导至另一组散热鳍片,搭配两颗12cm风扇,其中一颗反叶设计让冷空间穿过卡身末端排向CPU 区域。



采用 12VHPWR 供电接头
供电方面,GeForce RTX 4090 Founder Edition 采用12+4 Pin的12VHPWR供电接头,单一接头最高可提供600W供电,由于原生支持12VHPWR连接线的电源供应器太少,NVIDIA随产品附PCIe 8Pin x4转12VHPWR转接线,要记住转接线有物理限制,在其接触点开始磨损之前,可以重复插拔的最大次数为30 次,同时不要过份弯曲使用,否则可能会导致短路。

轴向式散热器设计
NVIDIA GeForce RTX 4090 Founder Edition 提供了 3 组 Display Port 1.4a + DSC 及 2 组 HDMI 2.1 影像输出,两种输出接口皆可提供最高 4K@240Hz 或 8K@60Hz 12bit HDR 分辨率输出,支持 VEGA DSC 1.2 无损压缩显示功能,单卡能提供最高 2 个 8K@60Hz HDR 显示输出,或是组合 2 组 DisplayPort 接口提供单一 8K@120Hz HDR 输出。

效能测试:对决 GeForce RTX 3090 Ti FE
要测试 GeForce RTX 4090 Founder Edition 显示卡当然要有一个强悍的对手,上代卡皇 GeForce RTX 3090 Ti Founder Edition 能扮演此一角色,方便大家了解新一代 GeForce RTX 4090 的效能水平。

时脉方面,NVIDIA GeForce RTX 4090 FE默认为2,235MHz基础频率、2,520MHz加速频率,支持GPU Boost4.0技术最高可达2,745MHz。
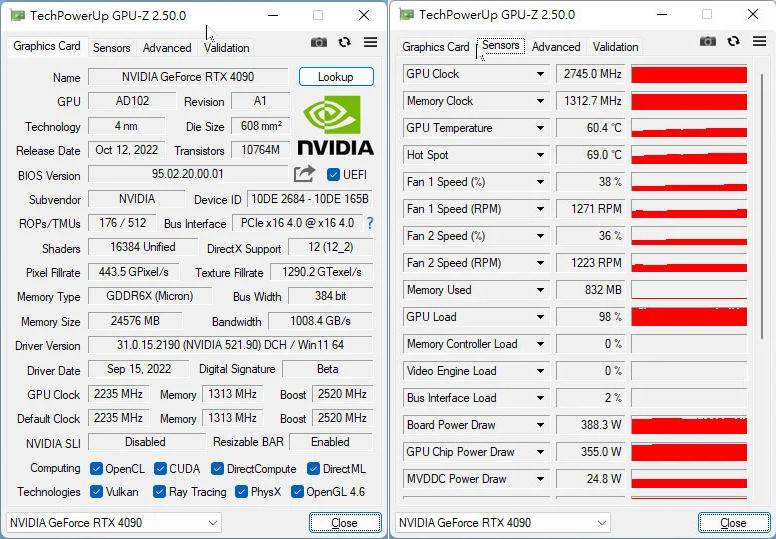
散热方面,NVIDIA GeForce RTX 4090 FE在约25°C的室温环境下闲置约30分钟,GPU温度维持在36°C。 接着采用 Furmark 进行3D负载测试,将显示卡烧机 30 分钟后,温度则提升至 70°C 的水平,GPU 时脉保持在 2,535MHz,在全负载时的时脉相较 NVIDIA GeForce RTX 3090 Ti FE 高了近 1GHz。

Open CL Memory Benchmark 内存带宽测试..
测试平台..
| CPU | Intel Core i9-12900K |
|---|---|
| 主板 | ASROCK Z690 AQUA OC |
| 显示卡 | NVIDIA GeForce RTX 3090 Ti FE |
| 显示卡 | NVIDIA GeForce RTX 4090 FE |
| 显示卡 | AMD Radeon RX 6950 XT |
| 内存 | G.SKILL DDR5-6000 CL30-38-38-39 16GB x 2 @1.35V |
| 系统 | Windows 11 Professional 22H2 |
| 驱动 | NVIDIA GeForce Driver 521.90 WHQL |
3DMark 测试..
3DMark 作为最广泛的 3D 性能基准测试,性能对比结果当然不可缺少,根据测试显示 GeForce RTX 4090 游戏性能相较上代产品有明显提升。
| Time Spy | Time Spy Extreme | |
|---|---|---|
| Radeon RX 6950 XT | 19457 | 9290 |
| GeForce RTX 3090 Ti | 19555 | 10046 |
| GeForce RTX 4090 | 33100 | 16861 |
| FireStrike | FireStrike Extreme | FireStrike Ultra | |
|---|---|---|---|
| Radeon RX 6950 XT | 41745 | 26992 | 14819 |
| GeForce RTX 3090 Ti | 36189 | 24486 | 14225 |
| GeForce RTX 4090 | 54895 | 39440 | 24946 |
3DMark Ray-Tracing 测试..
3DMark Port Royal 是首款针对实时光线追踪所设计的测试工具,支持 Microsoft DirectX Raytracing 技术,让玩家测试不同显卡对于光线追踪的效能,拥有第 3 代 RT Core 的 RTX 4090 绝对是神一般的存在,测试得分为 25995 大幅压倒 RTX 3090 Ti 与 RX 6950 XT。
| Port Royal | |
|---|---|
| Radeon RX 6950 XT | 10789 |
| GeForce RTX 3090 Ti | 14771 |
| GeForce RTX 4090 | 25995 |
游戏性能测试:
以下的游戏测试除另外指明外,全部皆以3840 x 2160分辨率全屏幕执行,画质皆设定为最高品质,若游戏支持光线追踪技术则同时将光追特效全开。 而DLSS方面则统一使用Performance设定,当中GeForce RTX 4090亦会启用DLSS 3中新增的Frame Generation技术。
A Plague Tale : Requiem 瘟疫传说:安魂曲
| 4K + DLSS Off | 4K + DLSS On | |
|---|---|---|
| GeForce RTX 3090 Ti | 44.9 | 80.4 |
| GeForce RTX 4090 | 78.5 | 174.9 |
Cyberpunk 2077 (New RT Overdrive)
| 4K RT + DLSS OFF | 4K RT + DLSS On | |
|---|---|---|
| GeForce RTX 3090 Ti | 24.1 | 66.4 |
| GeForce RTX 4090 | 43.2 | 149.8 |
F1 22
| 4K RT + DLSS OFF | 4K RT + DLSS ON | |
|---|---|---|
| GeForce RTX 3090 Ti | 60 | 137 |
| GeForce RTX 4090 | 96 | 232 |
Justice Online 逆水寒
| 4K RT + DLSS Off | 4K RT + DLSS On | |
|---|---|---|
| GeForce RTX 3090 Ti | 7.9 | 26.6 |
| GeForce RTX 4090 | 51.4 | 110.7 |
Microsoft Flight Simulator 微软模拟飞行
| 4K + DLSS OFF | 4K + DLSS ON | |
|---|---|---|
| GeForce RTX 3090 Ti | 54.1 | 81.7 |
| GeForce RTX 4090 | 77.4 | 169.9 |
Tom Clancy’s Rainbow Six Siege 虹彩六号:围攻行动
| 1080P | 2K | 4K | |
|---|---|---|---|
| GeForce RTX 3090 Ti | 592 | 513 | 321 |
| GeForce RTX 4090 | 613 | 586 | 517 |
Unreal Engine 5 : Lyra Demo
| 4K RT + DLSS Off | 4K RT + DLSS On | |
|---|---|---|
| GeForce RTX 3090 Ti | 58.1 | 114.3 |
| GeForce RTX 4090 | 90.7 | 197.2 |
DaVinci Resolve Studio 18 硬件编码性能测试:
除了游戏性能的提升外,对于许多创作者来说显卡的硬件的编解码速度同样重要。 NVIDIA GeForce RTX 4090 就拥有两个第 8 代 NVENC 编码器,不但新增了 av1 编码能力,在 H.264 及 H.265 编码速度上亦有明显的提升。
测试采用 DaVinci Resolve Studio 18 视频剪辑软件,分别使用 GeForce RTX 4090 及 RTX 3090 Ti 以 H.265 及 AV1 编码格式各輸出一條 4K 及 8K 的视频 ,结果显示RTX 4090的H.265编码速度比RTX 3090 Ti快了一倍以上,而在AV1编码上更比RTX 3090 Ti快了N倍,因为RTX 3090 Ti根本不支持 AV1 硬件编码。
| 测试项目 | GeForce RTX 3090 Ti FE | GeForce RTX 4090 FE |
|---|---|---|
| 4K30 – H.265 | 00 : 32 | 00 : 14 |
| 8K30 – H.265 | 01 : 55 | 00 : 46 |
| 4K30 – AV1 | 不支持 | 00 : 14 |
| 8K30 – AV1 | 不支持 | 00 : 50 |
*结果为输出视频完成时间,时间越短代表编码速度越快。
编辑评语..
NVIDIA GeForce RTX 4090 将游戏性能带到另一个高度,让所有3A游戏大作也可以用4K分辨率+RTX On运作,尤其在DLSS 3模式下其性能更是跳跃式成长,现时已知悉会有35款游戏支持DLSS 3,年底前将会有100款游戏支持。
相信在RTX 40系列推动下,RT On将会变成玩游戏的基本配置,不过NVIDIA真的需要在GPU功耗方面多下功夫,450W已经有点夸张了。
 微信扫一扫
微信扫一扫
相关推荐
-
盘点2022年11月游戏阵容!《Sonic Frontiers》《God of War: Ragnarok》《宝可梦 朱&紫》等游戏即将推出!
今年10月玩家入手了什么游戏?你们开始玩《Resident Evil Village Gold Edition》还是《Call of Duty: Modern Warfare II…
-
《HUMANKIND》首款资料片「Together We Rule」预购开启 将于11月9日推出
《HUMANKIND》的首款资料片「Together We Rule」将于11月9日与大型免费更新一起推出,现在预购可享9折优惠。 详情如下。 预购「Together We Rul…
-
驾车冲入新时代! 《F1》最新作《F1 22》确定7月登场支持VR虚拟现实功能
Codemasters与EA美商艺电宣布,EA SPORTS竞速游戏《F1 22》将于7月1日(五)在全球推出,带领玩家迈入《Formula 1》崭新时代。 玩家将可透过这款十年来…
-
2022年单机游戏推荐(最适合玩的5款大型单机游戏)
大家好!是我钱大游,现在每个玩家手机上都安装了不少的游戏,有的小伙伴喜欢玩大型单机游戏,而且这些都是耐玩,占用内存容量大,那么这5款大型单机游戏你玩过几款呢? 1、泰坦之旅 泰坦之…
-
《我的世界》1.19什么时候发布?
我的世界 在2021年的《我的世界》全球嘉年华Minecraft Live上,Mojang联合多位开发者为冒险家们带来1.19版本更新的相关介绍,Mojang宣布:《我的世界》将在…
-
未来iPhone 15高端款才配备新A系列处理器将成常态
不管是或苹果分析师郭明錤一致认为iPhone 14 Pro系列才会搭载A16芯片,而基本款iPhone 14和iPhone 14 Max会沿用旧款A15处理器芯片,最近郭明錤预测未…