
Intel i740 没跟到! Larrabee 拉拉比被砍掉! 这次一定要用贤者之石练成显卡! (疑? )
2021 年科技业界最震撼的消息,Intel 再度重返独立显卡绝对可以记上一笔! 并一口气宣布推出 Alchemist、Battlemage、Celestial、Druid 4 代产品。 以事后诸葛的角度来看,推出过程纵使不顺遂,历经驱动程序不成熟、一再延迟,甚至传出砍掉AXG事业部门还无法重练的消息,幸好终于在2022年10月推出第一世代最高阶ArcA770和Arc 750独立显示卡作品。
超越当代显卡的功能
目录
以第一世代 Alchemist 规格来看,Intel 的野心其实十分明显,包含硬件支持 DirectX 12 Ultimate 规格、硬件重新排序光线追踪工作、XMX 矩阵运算引擎、AV1 硬件编码、Smooth Sync,软件则推出 XeSS 人工智能超取样技术,功能上甚至还超越 AMD、NVIDIA 现有产品。 话不多说,赶快来看看 Intel 这块大饼是用什么好料画出来!?
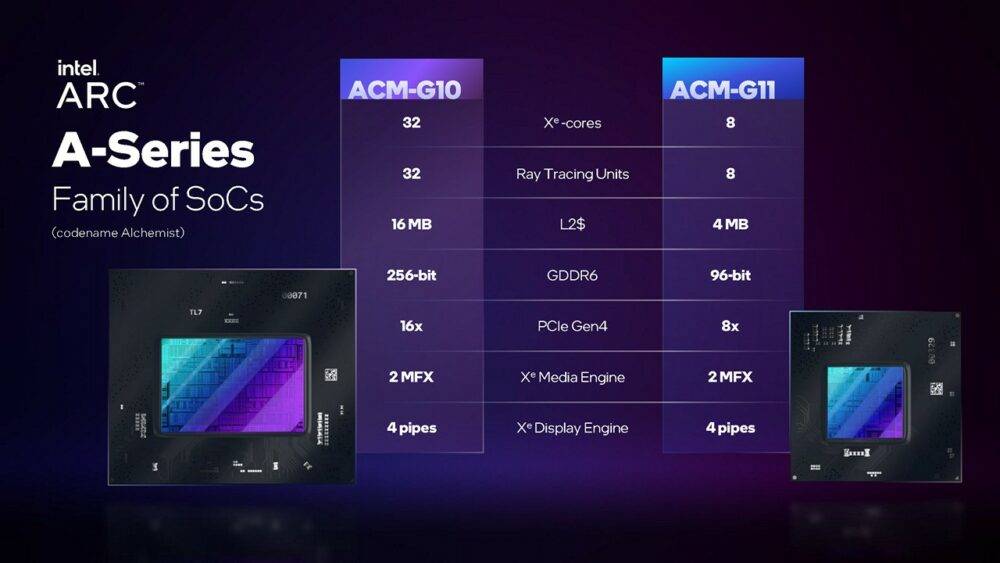

▼「千呼万唤始出来」,继 2022 年 6 月于正式开卖采用 ACM-G11 芯片设计的 Intel Arc A380 之后,2022 年 10 月于全球推出采用 ACM-G10 芯片设计的 Intel Arc A770/A750,Intel Arc A580 也会采用这个芯片版本。
第一世代采用 Alchemist 架构芯片预计将有 2 款,ACM-G11 是比较小型的设计,仅有 8 个 Xe 核心(1 个 Xe 核心约有内置显示绘图核心所称的16个EU、但须注意Xe 核心还多了一些东西)、GDDR6 内存通道宽度为96bit; ACM-G10 则是最大的设计,可达 32 个 Xe 核心,GDDR6 内存通道宽度则达256bit。
所有采用 Alchemist 架构的芯片均透过 TSMC N6 制程制造,ACM-G11 芯片尺寸约为 157mm2,内含 72 亿个晶体管; ACM-G10 芯片尺寸约为 406mm2,内含 217 亿个电晶体。 Intel 官方赋予这 2 款芯片制成的桌上型 Arc A380 和 Arc A770 独立显示卡,运作时脉在 2GHz 以上,TBP(Total Board Power)分别为 75W 和 225W。 当然,合作厂商可以根据需求自行调整。
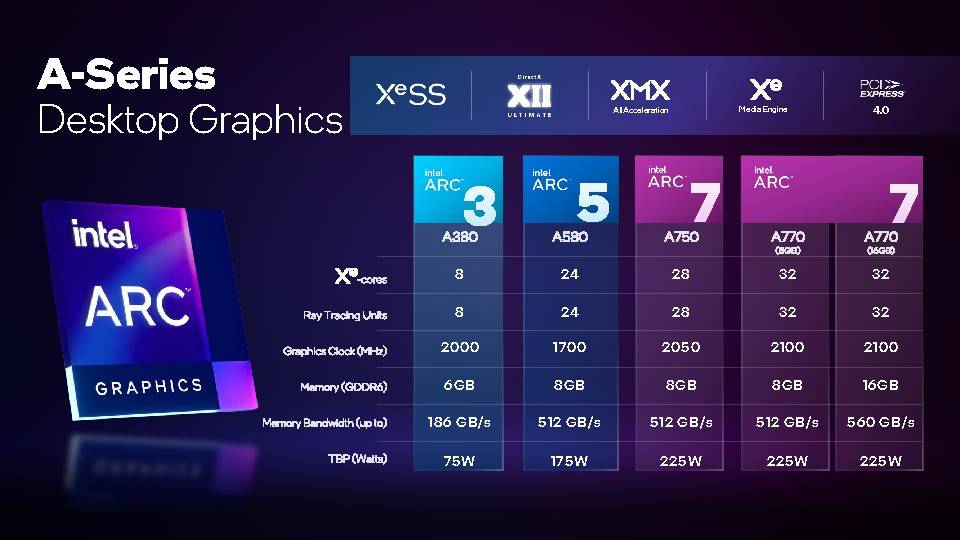
▼ 市场预计将会见到 5 款采用 Alchemist 架构的 Arc A 系列桌上型独立显示卡,Arc A770 则会推出 8GB 和 16GB 内存版本。 这系列显卡均具备同样的特效功能,仅以性能高低作为区分。
Xe-LP、Xe-HPG、Xe-HPC
Intel 原先预计推出 4 款针对不同市场的架构设计,内建图形显示 Xe-LP、游戏市场 Xe-HPG、数据中心 Xe-HP、高效能运算 Xe-HPC,但是 Xe-HP 已不会推出,仅做为自家开发工具使用,这一块数据中心市场目前由 Xe-HPG 补上,推出 Intel Data Center GPU Flex 系列。
另外一个比较有趣的部份,除了用于超级运算的 Xe-HPC 以外,其余全部不具备硬件 FP64 运算能力,需透过软体模拟,与 AMD、NVIDIA 切割市场而屏蔽硬件处理 FP64 速度的方式并不相同。 不过娱乐用显卡几乎不需要FP64运算能力,砍掉也无妨。

▼ Xe-HPG 相较于 Xe-LP,提供独立的浮点运算路径。 单一向量引擎宽度为256bit,支持8个FP32 SIMD运算。

▼ Xe-HPG 每个 Xe 向量引擎的后方还衔接1个宽度为1024bit的XMX矩阵引擎,提供更高的FP16/INT8运算能力,并额外支持BF16/INT4/INT2格式。

▼ 单一 Xe 核心之中,透过着色器每个时脉可执行16次INT8运算,使用DP4a指令集则是提升至每个时脉64次运算,XMX矩阵引擎则是大幅提升至每时脉周期256次运算,加快人工智能推论结果产出。

▼ 单一 Xe 核心具有16个矢量引擎、16个矩阵引擎、192KB L1快取∕Shared Local Memory。
Xe-HPG 的组成单元最小为 Xe 核心,每个 Xe 核心内部有16个矢量引擎和16个矩阵引擎,并拥有自己的储存∕加载单元、指令缓存、L1缓存 ∕ Shared Local Memory。 每个 Xe 核心也对应 1 个执行绪排序单元和 1 个光线追踪单元,再加上取样单元、几何单元、光栅单元、HiZ 剔除单元、像素后端单元…… 等,4 个 Xe 核心组合成 1 个 Render Slice。

▼ Xe-HPG 每个 Render Slice 包含 4 个 Xe 核心和 4 个光线追踪单元。
Xe-HPG 的光线追踪单元除了目前大家熟知的 Ray Traversal、Bounding Box Intersection、Triangle Intersection 功能之外,Intel 于今年 4 月底举行的 GDC 2022 向外宣布,Xe-HPG 光线追踪工作还能够以硬件的方式,将工作内容相近的光线追踪线程排在一起运算,这有助于资源重复利用并加快运算速度。 竞争对手 NVIDIA 直到 GeForce RTX 40 系列才加入,AMD 则还在苦苦追赶光线追踪各项功能当中。
延伸阅读:A Quick Guide to Intel’s Ray-Tracing Hardware | GDC 2022 | Intel Software
另一方面,为了加速Bounding Box Intersection、Triangle Intersection等作业,光线追踪单元内建1个BVH(Bounding Volume Hierarchy)快取,每个光线追踪单元内含2条TraversalPipeline,峰值效能加总每个时脉可达12次Box Intersection和1次 Triangle Intersection。
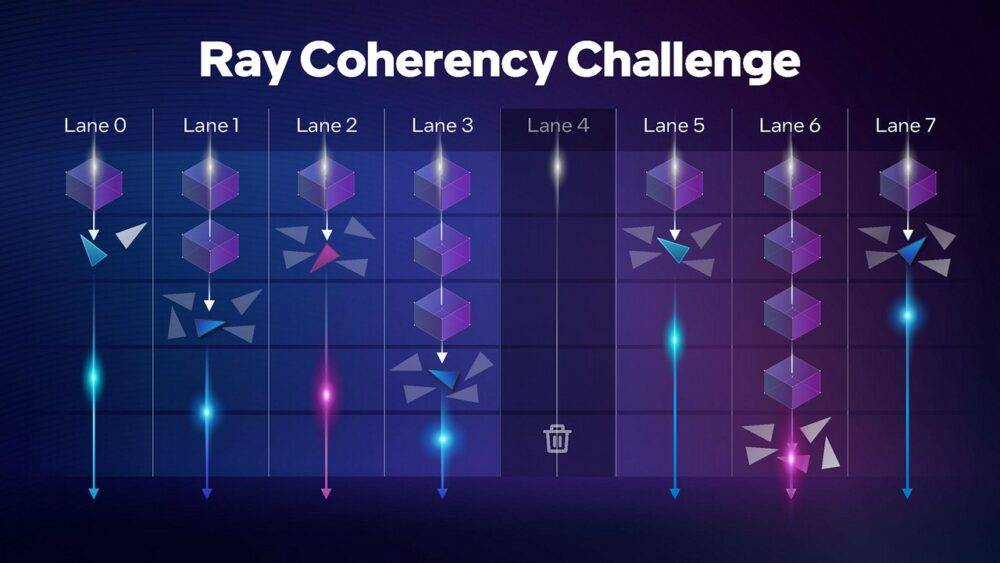
▼ 不同的光线追踪工作,从摄影机反向射出的光线有可能很快就返回碰撞结果,也有可能碰撞到物体后再反射进入另外的执行循环,也有可能完全没有碰撞到场景中的物件,因此每个光线追踪工作时间、所需资源不尽相同,容易造成硬件资源的浪费。

▼ Xe-HPG 执行绪排序单元能够将相近的光线追踪工作排在一起处理,达到资源重复利用、加速运算的效果。

▼ Xe-HPG 单一光线追踪单元,每个时脉最高可达 12 次 Box Intersection 和 1 次 Triangle Intersection。
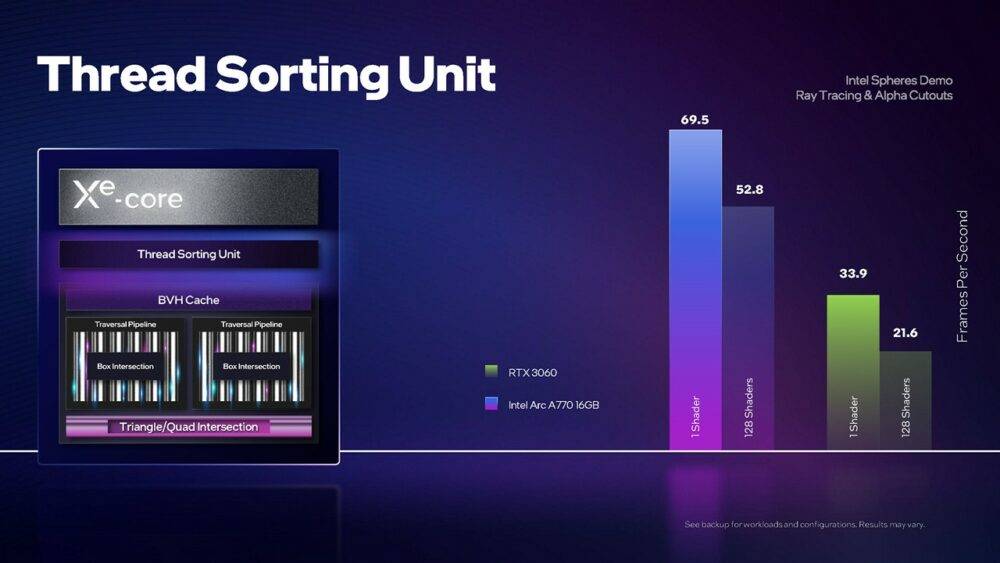
▼ 相较于不具备着色器执行绪排序功能的 GeForce RTX 3060,Arc A770 光线追踪效能优势十分明显。
媒体引擎支持AV1硬件编码
Alchemist 架构显卡另外一项创举,是在媒体单元中新增 AV1 硬件编码能力(第 12 代、第 13 代 Intel Core 处理器仅内建 AV1 硬件解码能力),最高可达 8K60 12bit HDR 硬件解码、8K 10bit HDR 硬件编码,原先 H.264(AVC)/H.265(HEVC) 硬件编解码、VP9 硬件解码也继承下来。 从 Sandy Bridge 世代 Intel HD Graphics 就具备的 VC-1 硬件解码功能则被拔除,毕竟现在使用 Windows Media Video 技术的视频,已经比日本制压缩机还要稀少。

▼ Alchemist 架构的媒体引擎支持 AV1 12bit 硬件解码和 AV1 10bit 硬件编码。
4 条画面输出通道、简单却有效的 Smooth Sync
Alchemist 架构具备4条画面显示输出通道,其中1条还针对低功耗运作优化,并支持DisplayPort 1.4/2.0 10Gbps、HDMI 2.0b,最高同步输出4个4K120HDR画面或是2个8K60 HDR画面。 如果需要支持HDMI 2.1,就须另行在显卡上安装1个协议转换芯片。

▼ Alchemist 架构具备 4 条画面显示输出通道,原生支持 DisplayPort 1.4/2.0 10Gbps、HDMI 2.0b。
自从NVIDIA推出G-SYNC之后,「画面显示垂直同步」议题就不断地受到大家关注,竞争对手AMD推出FreeSync,视频产业标准制定协会VESA则是推出AdaptiveSync,其它还有以取巧方式兼顾画面品质与输出延迟的各项技术。 Intel 在此则是拥抱 VESA 标准 AdaptiveSync,并把自家输出画面缓冲区最后 1 张完整画面的技术,称之为 Speed Sync(运作原理和 NVIDIA Fast Sync 相同)。
Alchemist 架构还支持另一种Smooth Sync,基本上与完全不做任何垂直同步的画面输出方式相同,当显卡画面输出速率与屏幕显示速率不同时,就会观察到撕裂现象。 不过Smooth Sync会在前一张画面和后一张画面交界处加入dithering filter,让画面撕裂看起来不那么地明显,且适用于一般屏幕。

▼ Alchemist 架构支持 3 种显示画面撕裂的改善方式,分别为 AdaptiveSync、Speed Sync、Smooth Sync。
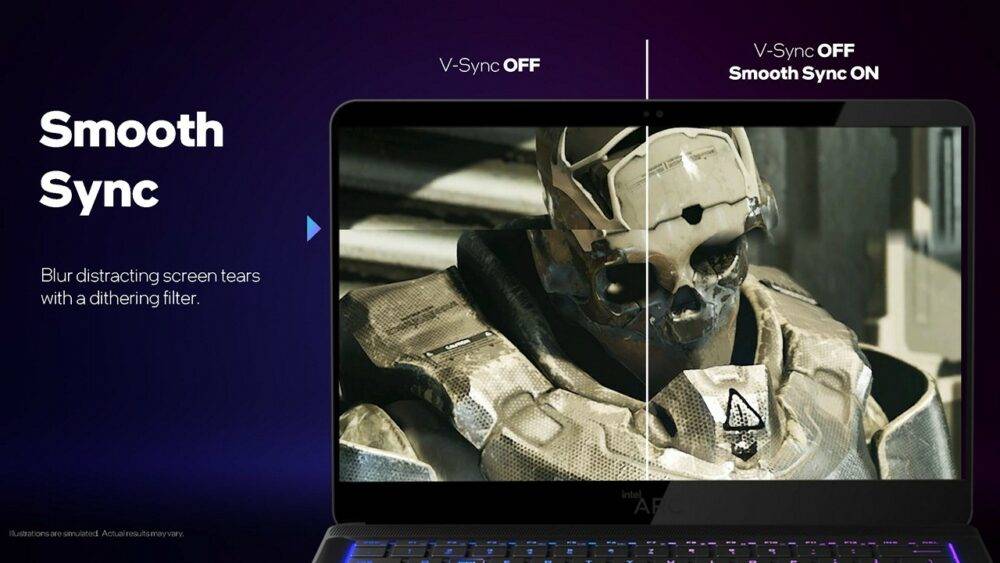
▼ Smooth Sync 显示画面仍旧有撕裂现象,但在前一张画面和后一张画面交界处加入 dithering filter 糢糊不连续边界,让人眼不易察觉画面撕裂,是个十分聪明的作法,并兼容所有游戏和一般屏幕。

▼ Intel Arc Control 公用程序也会加入显示卡遥测、OSD 信息显示、超频等功能,而且「不需要登录帐号」。 部分游戏则支持 Automatic Game Highlights 功能,自动录制一小段值得纪念的视频。
XeSS 人工智能超取样技术
NVIDIA 有 DLSS,Intel 也有与之对应的 XeSS 技术,但相较于 DLSS 只能在具备 Tensor 核心的显卡使用,XeSS 则能够在没有 XMX 矩阵引擎的情况下,通过 DP4a 指令以类似的实作方式呈现(显示卡需支持 HLSL Shader Model 6.4),特别是还没有类似人工智能解决方案的 AMD 显示卡。 XeSS 需要游戏开发商将此功能整合在游戏之中,无法如同 AMD RSR(Radeon Super Resolution)直接从驱动程序开启即可。
XeSS 同样通过深度学习算法,训练模型能够从低分辨率画面生成高分辨率画面,XeSS 要求游戏提供提供低分辨率画面、高分辨率动态矢量,若无法提供高分辨率动态向量信息,也可以提供低分辨率动态向量和深度信息; 摄影机朝向游戏场景拍摄时则需要加入 jitter(建议使用 Halton(2, 3) 序列)略为移动拍摄位置(以便取得更多画面资讯并强化反锯齿效果),也会建议开发商将 Mipmap 偏移适度地调低(使用较高分辨率的材质)。 最后输出的高分辨率图片,也会回馈至 XeSS 当中,以便处理对象材质被遮蔽,忽隐忽现容易让画面破碎的问题。
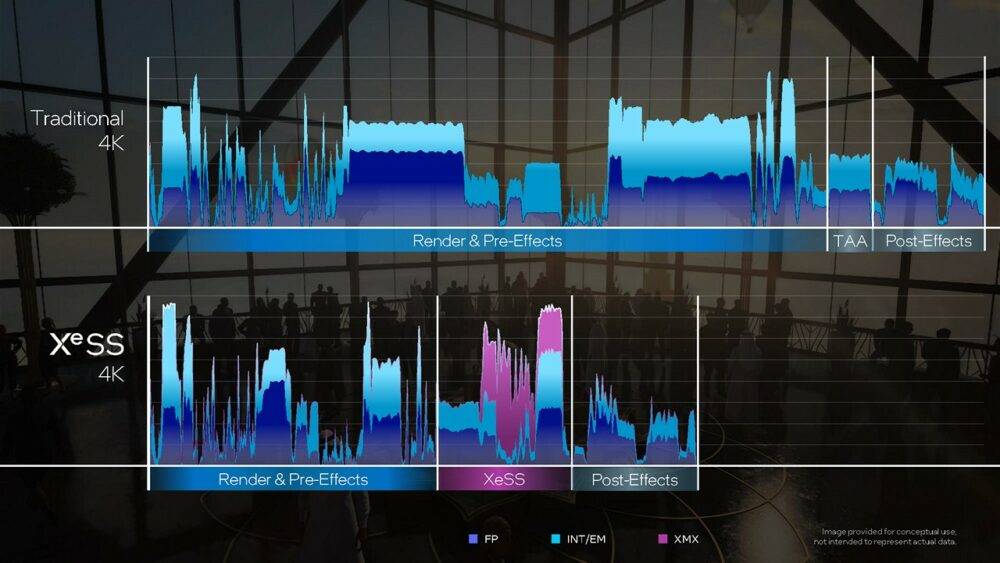
▼ 藉由 XeSS 技术,就能够以较低的分辨率进行画面渲染工作,提升游戏画面帧数,最终亦能够输出高分辨率、高品质的画面。
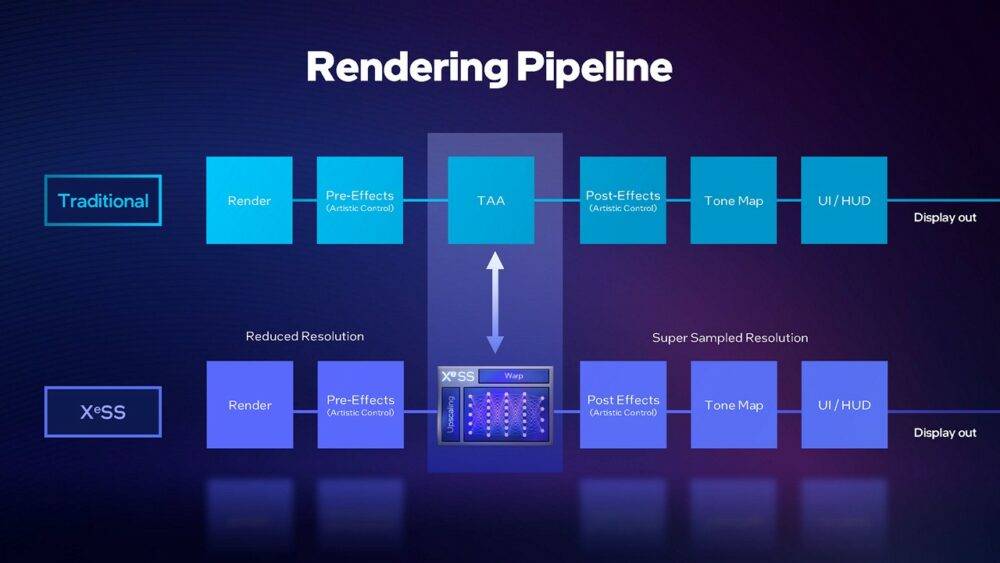
▼ 以画面渲染流程来看,XeSS 主要是取代了过往 TAA 阶段。
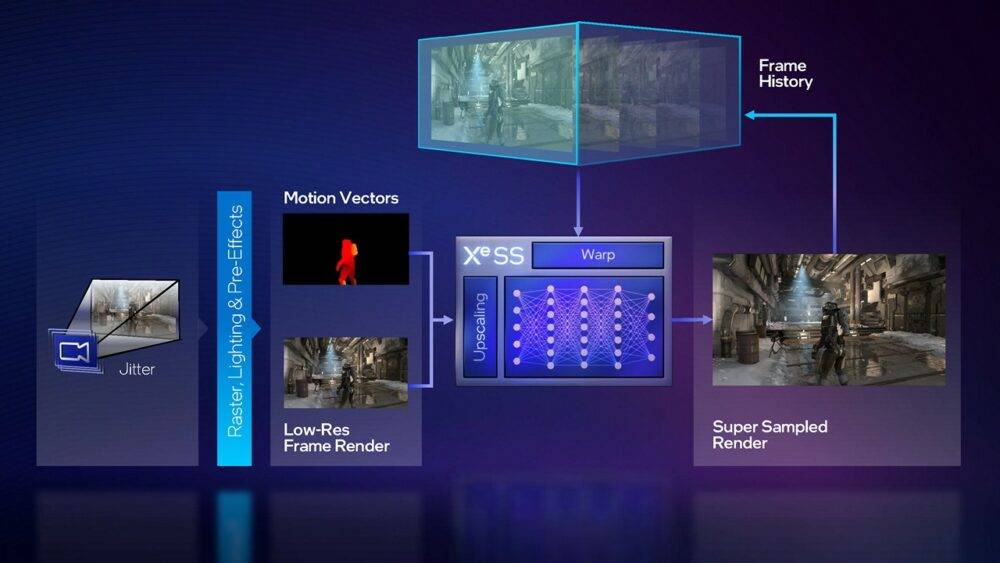
▼ XeSS 需要整合至游戏当中,提供较低分辨率画面和动态向量信息,生成的较高分辨率画面也会持续地回馈至 XeSS 当中。

▼ XMX 和 DP4a 执行 INT8 数据类型的运算量比较。

▼ XeSS 不限 XMX 矩阵引擎的显卡才能够执行,可执行 DP4a 指令的 Intel 内置图形显示或是其它支持 HLSL Shader Model 6.4 显卡也能够使用,只是运算能力有限无法使用较复杂的模型。

▼ XeSS 将提供 4 种画质选项:Ultra Quality、Quality、Balanced、Performance,其内部渲染分辨率大约是画面分辨率的 0.766 倍、0.666 倍、0.583 倍、0.5 倍。

▼ ACM-G10 SoC 整体功能架构图。

▼ Intel Arc A770 / A750 Limited Edition 规格一览。 Intel Arc A770 8GB建议零售价将从329美元起跳、16GB则从349美元起跳,IntelArc A750建议零售价将从289美元起跳。
比较可惜的是由于某些缘故,Intel Arc A系列独立显示卡错失最好的上市时间,整体软、硬件架构开发方向也偏向最新API(DirectX 12、Vulkan),DirectX 9/10/11、OpenGL等需要驱动程序优化的API,目前Intel仍持续努力当中,就连内存控制器的设计方式,也以支持Resizable BAR为主。 Intel Arc A 系列独立显示卡若是安装在有些年纪,不支持 Resizable BAR 的电脑系统上,会见到幅度可观的效能减损现象。
幸好Intel在定价策略上相当大方,将以Tier 3(使用旧API且未优化)游戏内部测试的效能结果进行定价,因此消费者可以使用比较便宜的价格,获取较高的Tier 1(使用现代API且已优化)、Tier 2(使用现代API但未全面优化)游戏效能,算是这位刚踏入独立显示卡市场的玩家,给大众的福利。
 微信扫一扫
微信扫一扫
相关推荐
-
《超级马力欧:奥德赛》奥德赛都市国月亮分布在哪?
奥德赛都市国月亮 Switch游戏大作《超级马里奥奥德赛》已于10月27日发售,游戏中有总计数百个月亮分布在各个地图中等待你收集,其中都市国共有81个月亮。 一,月亮具体分布概况图…
-
棋盘战斗玩法《英雄骰子》上架开服 三上真司领军开发首款手游
由三上真司率领的 Tango Gameworks 开发,ZeniMax Asia 发行的首款棋盘战斗手机游戏《英雄骰子》(ヒーローダイス),今天已经在日本 App Store / Google Play 商店上架推出!
-
赚钱小游戏每天50元(一小时可以赚50元的游戏)
现在喜欢玩游戏的人不少,毕竟下班后玩玩游戏的话,也可以消遣一下无聊的时间。但你知道吗?其实,在我们玩游戏的时候,也是可以挣钱的哦。比如说,近些年来很火的小游戏,不就是玩游戏挣钱的一…
-
《绝地求生》公布 PGC 世界冠军赛赛制 2022年PUBG电竞最终战11月迪拜上演
韩国魁匠团公司(KRAFTON, Inc.)今(22)日公开关于PUBG Global Championship(中文名称:PGC世界冠军赛,简称PGC)2022完整细节,PGC将…
-
新 iPad 第 10 代规格流出,带你了解最新的 4 大更新重点
苹果的iPad 9以便宜的定价锁定了许多入门用户、学生、轻度用户的市场,虽然是平价款但也是4款iPad产品线上重要的一环,而近日有分析师透露了下一款的iPad第10代规格。 iPa…